The following article talks about DevOps for app teams, how to setup an Internal Developer Platform (IDP) to fulfill the DevOps cycle, what is and how to mitigate Ops Sprawl, and why you must care about the cloud vendors you will rely on.
https://thenewstack.io/a-guide-to-open-source-platform-engineering/
BILBAO — The rise of platform engineering in 2023 is part of a pendulum swinging back away from developer autonomy but not all the way back to Waterfall command and control. We want developers to retain their sense of choice, encouraging the problem-solving side of these creative workers. But we also want to cut down on tool sprawl and cut the cost and risk that can come with it.
This week at the Linux Foundation’s Open Source Summit Europe, open source community members looked to highlight the on-ramp to getting things done with an open source stack. That included Gedd Johnson, a full-stack engineer at Defense Unicorns, a consultancy that builds open source DevSecOps platforms, including for the U.S. Department of Defense, talking about how to get on board with this recent trend of platform engineering.
Most importantly, Johnson’s talk exhibited how to achieve the benefits of open source platform engineering, diagramming an example of building a Kubernetes-based platform entirely on free and open source software.
The last few decades delivered great advances in infrastructure; now, it’s time to build apps that make the most of those new tools. VMware Tanzu helps you build new apps, modernize existing ones, and evolve your development process around cloud native technologies, patterns, and architectures.
Oops! DevOps Causes Ops Sprawl
“Adopting a DevOps culture means that the team has full ownership over the entire software lifecycle,” Johnson said. “The team is proficient across the entire stack,” which they’ve chosen to suit their unique context.
But with great freedom and responsibility comes great inefficiency.
“If you have disparate app teams that have adopted a DevOps culture, and they’re owning their own processes from end to end, those teams have a tendency to inadvertently silo themselves,” he said. “And if this happens, you can bet that multiple app teams are going to be solving the same problems over and over again, and maybe not necessarily at the application code level.”
He gave the example of an organization built this way on Amazon Web Services.
“A very popular method for deploying on AWS is with Elastic Container Service, or ECS. And if you have multiple app teams using ECS, and those app teams are siloed away, you can bet that they’d all solve the problem of deploying their app on ECS in their own way,” Johnson said.
Some app teams might take an Infrastructure as Code approach in TerraForm. Others might just “ClickOps” their way through the AWS console, scrolling through menus for their right choice. Each team is likely using load balancers in front of their apps, but may choose different ones for different reasons.
“So even in just one AWS service, there’s a multitude of different ways to do things, and I’m just talking about ECS,” he observed. “In the AWS on the whole, there are hundreds of ways to deploy an app and, without any org level guidance and opinionation, you end up with what are called ops sprawl.”
Ops sprawl is what Johnson calls when a cloud environment is overloaded with somewhat differing, but often repeat work, usually without the context of why a tool or process was chosen in the first place. This sprawl happens across all these accidental silos — an ironic casualty of DevOps, which was born to break down silos.
“This is also likely very expensive for your work because you likely have orphaned resources lying all over your cloud accounts,” he continued. “Lastly, security and compliance can become especially difficult if each app team has their own snowflake deployment process that means your security and compliance engineers have to re-accredit each of these individual snowflake applications.”
Platform Engineering to the Standardization Rescue!
Everyone has different explanations for what is platform engineering. Johnson says, “The goal of platform engineering is to standardize the process for deploying and operating applications as well as their underlying infrastructure.” A platform strategy kicks off by discovering the disparate tools and processes used by each app team, and then “forms an opinion on the best, most robust and most relevant to our contexts methods for deploying an application and operating its infrastructure,” therefore laying, enforcing and automating the golden path to production.
What’s in a golden path besides yellow bricks? This can range from creating reusable continuous integration pipelines that enforce static code analysis and dependency scanning all the way to a streamlining of your (probably costly) AWS accounts by “scoping applications to use the minimum set of permissions necessary to operate,” he said.
Now, if you’ve been reading The New Stack for a while now, you know that an internal developer platform isn’t successful if it’s a top-down initiative — that’s a surefire plan to build just what your engineers do not want. So you have to be careful in internally launching your platform as standardization and opinionation start to make people “rightfully” nervous that their autonomy is being stripped away — after all, in the DevOps world their team had all the control.
“It can sound like platform engineering is here to take that freedom away and go back to a world where other teams who don’t have an appropriate level of context are dictating how an app team does their job,” Johnson warned. “In reality, the crux of platform engineering is bouncing this level of freedom you give developers with the underlying opinionation of the platform.”
Or, as Spotify puts it, standards can set you free.
How to Build an Open Source Internal Developer Platform
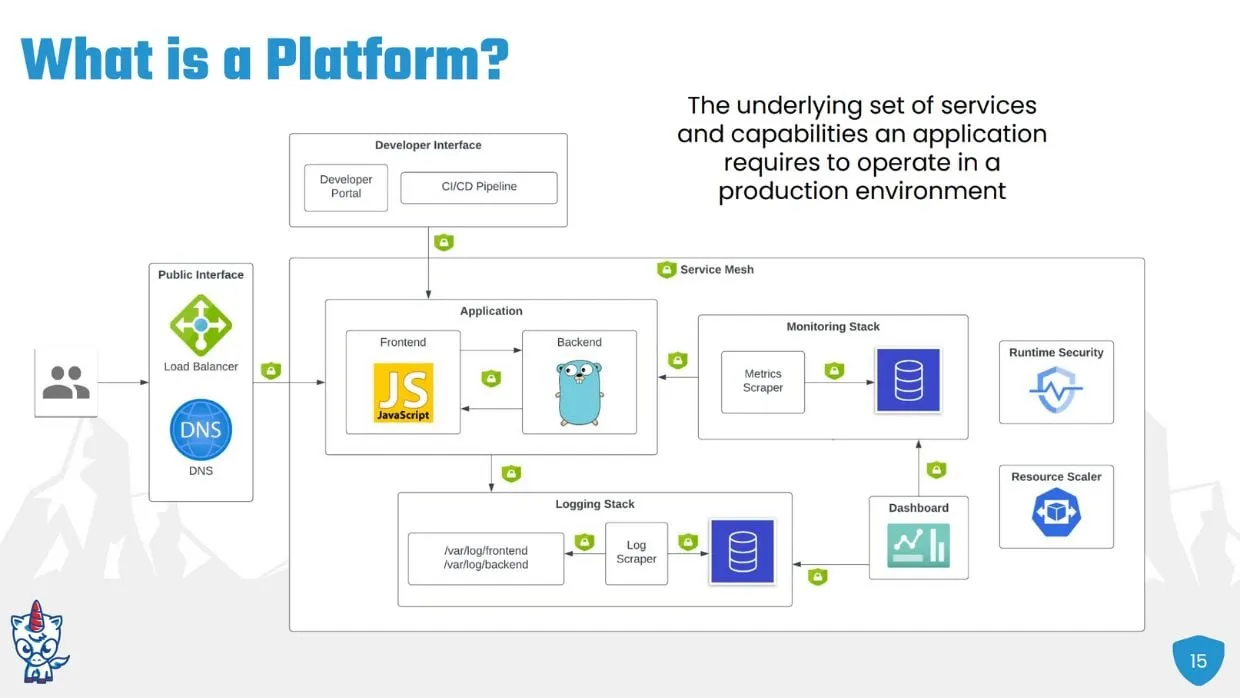
The underlying technical stack needed in a platform as listed in article
In order to sell your DevOps-driven apps teams on this new pseudo-freedom, you need to explain to them what platform engineering is — and being such a nascent discipline, the industry hasn’t exactly coalesced on a single definition of internal developer platform (IDP).
“In its simplest form, a platform is just the underlying set of services and capabilities that an application requires to run effectively in a production environment,” Johnson said. Platform-driven automation makes it really easy to do the right things and really hard to do the wrong ones.
While every IDP should naturally be unique based on the results of your ops sprawl crawl, there is a certain pattern his team has uncovered for what goes into a completely free open source platform engineering strategy. Johnson talked us through what to build around that frontend and backend layer that you want your app team to focus on for value delivery to end users.
IDP Demand #1: A Monitoring Layer
The monitoring and observability needs are likely the same across your organization, making it a fair place to start your platform journey.
“When this app gets deployed, engineers are going to want to know if it actually got deployed, is it healthy, is it reachable and also how is this app performing,” Johnson said, which is why, at bare minimum, any abstraction must include assurances and health checks, monitoring of connectivity, and “some quantitative insight into how the app is performing from like a CPU and networking perspective.”
He suggests the Kubernetes dashboard Metrics Scraper to achieve this.
IDP Demand #2: A Logging Layer
Engineers are going to want to view logs in real-time, as well as query historical logs, which means you need a logging stack, says Johnson. “The app is going to emit logs to a particular directory, and we’ll need a log scraper to grab logs from that directory and then forward them on to a log database.”
Logalyzer and OmniSci are popular open source log scrapers.
IDP Demand #3: A Dashboard
Then you need a dashboard to make it easy for engineers to observe their logging and monitoring. In order to do this safely, Johnson says this requires network encryption with TLS. Each application can implement its own TLS or you can point them onto some centralized certificate authority or CA server, and then manually pass around certificates — but anything manual contributes to your ops sprawl. So he offers the alternative of adding a service mesh, which performs the same capabilities, without having to touch application code.
IDP Demand #4: Load Balancer and DNS
A load balancer and DNS records will make the app accessible to its end users by creating a public interface.
IDP Demand #5: An Internal Developer Portal
This is where your platform engineering strategy will sink or swim. This developer portal should enable self-service so devs can work out what they need to do. It also should give them an easy way to view all these dashboards in one place, and give them a snapshot of the health of their app at all times. In addition, this dev portal lets them see what other teams are doing and who owns what, giving cross-organizational clarity and enabling reusability.
The internal developer portal should give them confidence that platform engineering is the way forward and make them want to actually adopt it.
IDP Demand #6: A Resource Scaler
“As more users interact with the application, and with the platform, we’ll probably want some mechanisms to scale up and scale down these various resources,” Johnson said,” so we’re making efficient use of the underlying compute that this is all running.” He suggests the Kubernetes resource scaler.
IDP Demand #7: Security at all Layers
“At some point, either the app or one of these platform components will have a zero-day critical security vulnerability, and this system will get hacked,” he warned. This demands a runtime security component to identify this vulnerability and to alert the team.
Build or Buy?
Going the free open source software route is not typically free in terms of time or energy. “There is basically an endless number of moving parts and tech decisions that you have to make to build something that your app devs actually want to use, and is easy to operate,” Johnson said. This is why many orgs choose to simply outsource it to their cloud provider.
However, in the highly regulated, Egress-limited environments where Defense Unicorns is working, what the big three offer may not be enough, leaving you to build your own.
Bonus is that by going the open source route, you’re able to evade vendor lock-in.
An Open Source Platform Engineering Case Study
Defense Unicorns chooses to build their open stack with Kubernetes, which it calls a cornerstone to platform engineering — as well as often the trigger to go the platform route.
“At its core, all Kubernetes does is provide a really robust and extensible API for managing containers. And this API is so popular that Kubernetes has become the de facto standard for deploying containers, both on-prem and in the cloud.” But, Johnson warned, “When you choose to adopt Kubernetes, many of those platform components that your cloud provider was providing you, you now own and you now have to operate and maintain and update.”
This is why he recommends having a team of platform engineers dedicated to building and maintaining — and of course in tight feedback loops with their internal app developer customers. But, the benefits typically outweigh the cost, he argues, because, by “using Kubernetes as a base, we can build this entire system using exclusively free and open source software.”
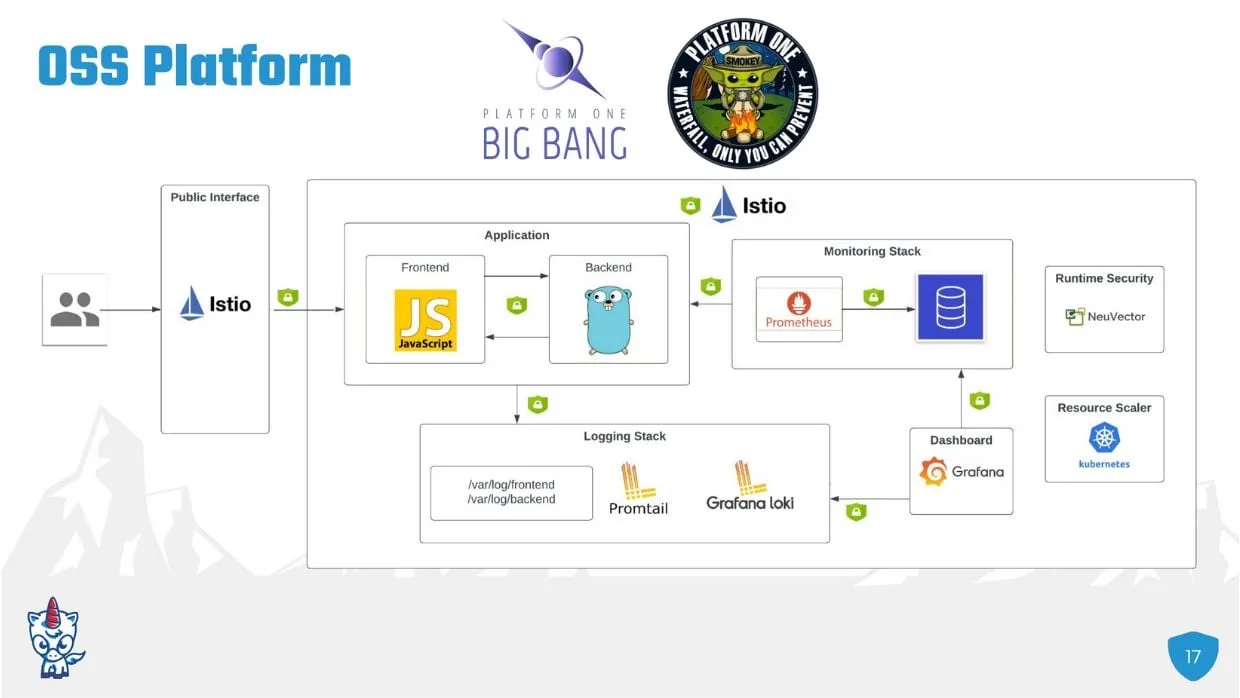
Big Bang architecture as described within piece
Johnson shared with the OS Summit Big Bang which was created and then outsourced by the Department of Defense’s Platform One DevSecOps program. “Big Bang is an open source declared baseline of applications and configurations used to create a secure Kubernetes-based platform,” he said, which was created by the U.S. Air Force.
Big Bang aims to take the most widely used and adopted open source components and bundle them together in a single Helm chart that can be deployed together. These free and open source tools included are:
- Logging stack – Promtail and Grafana loki.
- Monitoring stack – Prometheus.
- Dashboard – Grafana.
- Service mesh – Istio to secure traffic between those platform components and for Egress for the cluster.
- Runtime security – NeuVector, monitoring for cluster anomalies or intrusions.
- Resource scaler – Kubernetes.
- Continuous delivery – Flux, which has the concept of the Helm release.
- AWS EKS cluster.
- EBS CSI driver.
Essentially, Johnson explained, “Big Bang itself is a Helm chart made up of Flux Helm releases for all of these various platform components.” Big Bang provides the default configuration, which automatically wires together many of the platform components.
He live-demoed building it on stage, and, within a few minutes, was able to check the health and connectivity of just under 50 pods and the virtual services, including CPU and memory utilization.
“And you have all these fancy charts to show your boss and all I’m checking here is that like, okay, metrics data is definitely being calculated and collected and we can view it so now for logs, what we can do is go to this explorer tab in Grafana,” Johnson said. In addition, with this open source platform engineering stack, you can see the most recent laws and query historical logs.
You train NeuVector in discovery mode for a bit and then switch it over to protect, “and it will use what it learned in discovery mode to it will use what it learned in discovery mode as heuristics for detecting various anomalies and intrusions and you can even set it up to automatically neutralize certain behaviors.”
Platform Engineering Lessons (from One of the Biggest AWS Bills in the U.S.)
The Department of Defense is a massive organization which makes it unsurprising that it experienced a lot of ops sprawl across hundreds of accounts, with each app team owning their own process, kind of doing whatever they wanted.
Add to this, these applications are operating within highly regulated environments, handling highly sensitive data. Any baseline architecture has to comply with NIST 800-53 requirements, across hundreds of apps teams.
“And because of this amount of ops sprawl, it took security teams an egregious amount of time to accredit these apps to run in the various regulated environments,” Johnson said.
They were actually able to build and deploy their open source internal developer platform in six months.
The main goal though — like for most IDPs — is whether it is adopted. Johnson said two things that must be true of internal developer platforms:
- It should make developers’ lives easier.
- It should enhance workflows.
“If the platform doesn’t do that, then fundamentally like we have missed the mark.”
And there were some roadblocks to adoption along the way. First, they realized that, while many teams were in the cloud running on AWS, very few were actually containerized — a prerequisite to running in Kubernetes. Most were either running in a virtual machine or completely serverless using lambdas.
So before they could on sell people on the platform, they actually needed teams to commit a few engineering cycles to containerization — which most teams were reluctant to do.
“In the beginning, we were marketing this platform more towards security and compliance engineers, and really highlighting the value prop of automatically satisfying all of these security controls. So there was less emphasis on the actual app devs,” Johnson admitted.
In order to get the app teams on board, they decided to inner source the work, and “then invited them to come build with us and encouraging these community adoptions and being transparent with what we’re building.”
And while this was happening, even though the ops sprawl was starting to get under control, Johnson’s team still had to run and manage Kubernetes and Big Bang for those almost 50 pods. “And when I say manage, I mean things like checking for image updates, and refactoring whatever upstream Helm chart has breaking changes and its values — and that happens way more often than you think.”
He’d find himself refactoring the logging staff for the tenth time across the many ways AWS does logging.
“Depending on how fast the team moves and the amount of changes being made, the operational overhead of running a homegrown, Kubernetes-based platform, it can get pretty absurd,” Johnson said. “So the lesson learned there is, when you’re architecting a platform, don’t forget to weigh [in] that operational overhead.”
And don’t assume that Kubernetes is the right choice for all organizations and all platforms — have a data-driven identified need for Kubernetes. Once you commit to Kubernetes, it’s hard to back out of that technical decision.
In the end, those original six months to build turned into a year. He learned that the best platforms come from extensive user research up front and then building smaller to fail faster.
Finally, Johnson advised that platform teams focus on the problem, not the tech: “The core problems that all these buzzwords are trying to get at are like, how do we make software development suck less and how do we build better products?”
#reads #the new stack #open-source engineering #platform engineering #devops #aws