The following is a port mortem on the DNS incident that lead to some Cloudflare data centers to reject DNS queries and thus clients couldn’t resolve domains operated by Cloudflare. This incident was caused by a leap second bug, which occurred on New Years Eve 2017.
Leap seconds are a “one-second adjustment” that are occasionally applied to Coordinated Universal Time (UTC), to accommodate the difference between precise time (International Atomic Time (TAI), as measured by atomic clocks) and imprecise observed solar time (UT1), which varies due to irregularities and long-term slowdown in the Earth’s rotation. Leap seconds are added to UTC to ensure that the difference between UTC and the actual solar time on the earth’s rotation does not exceed 0.9 seconds.
In short, when a leap second is added, for example on December 31, 2016, the following is noticed:
23:59:58 UTC on December 31, 2023
23:59:59 UTC on December 31, 2023
23:59:60 UTC on December 31, 2023 (leap second inserted)
00:00:00 UTC on January 1, 2024 (next second after the leap second)
https://blog.cloudflare.com/how-and-why-the-leap-second-affected-cloudflare-dns/
At midnight UTC on New Year’s Day, deep inside Cloudflare’s custom RRDNS software, a number went negative when it should always have been, at worst, zero. A little later this negative value caused RRDNS to panic. This panic was caught using the recover feature of the Go language. The net effect was that some DNS resolutions to some Cloudflare managed web properties failed.
The problem only affected customers who use CNAME DNS records with Cloudflare, and only affected a small number of machines across Cloudflare’s 102 data centers. At peak approximately 0.2% of DNS queries to Cloudflare were affected and less than 1% of all HTTP requests to Cloudflare encountered an error.
This problem was quickly identified. The most affected machines were patched in 90 minutes and the fix was rolled out worldwide by 0645 UTC. We are sorry that our customers were affected, but we thought it was worth writing up the root cause for others to understand.
A little bit about Cloudflare DNS
Cloudflare customers use our DNS service to serve the authoritative answers for DNS queries for their domains. They need to tell us the IP address of their origin web servers so we can contact the servers to handle non-cached requests. They do this in two ways: either they enter the IP addresses associated with the names (e.g. the IP address of example.com is 192.0.2.123 and is entered as an A record) or they enter a CNAME (e.g. example.com is origin-server.example-hosting.biz).
This image shows a test site with an A record for theburritobot.com and a CNAME for www.theburritobot.com pointing directly to Heroku.
When a customer uses the CNAME option, Cloudflare has occasionally to do a lookup, using DNS, for the actual IP address of the origin server. It does this automatically using standard recursive DNS. It was this CNAME lookup code that contained the bug that caused the outage.
Internally, Cloudflare operates DNS resolvers to lookup DNS records from the Internet and RRDNS talks to these resolvers to get IP addresses when doing CNAME lookups. RRDNS keeps track of how well the internal resolvers are performing and does a weighted selection of possible resolvers (we operate multiple per data center for redundancy) and chooses the most performant. Some of these resolutions ended up recording in a data structure a negative value during the leap second.
The weighted selection code, at a later point, was being fed the negative number which caused it to panic. The negative number got there through a combination of the leap second and smoothing.
A falsehood programmers believe about time
The root cause of the bug that affected our DNS service was the belief that time cannot go backwards. In our case, some code assumed that the difference between two times would always be, at worst, zero.
RRDNS is written in Go and uses Go’s time.Now() function to get the time. Unfortunately, this function does not guarantee monotonicity. Go currently doesn’t offer a monotonic time source (see issue 12914 for discussion).
In measuring the performance of the upstream DNS resolvers used for CNAME lookups RRDNS contains the following code:
// Update upstream sRTT on UDP queries, penalize it if it fails
if !start.IsZero() {
rtt := time.Now().Sub(start)
if success && rcode != dns.RcodeServerFailure {
s.updateRTT(rtt)
} else {
// The penalty should be a multiple of actual timeout
// as we don't know when the good message was supposed to arrive,
// but it should not put server to backoff instantly
s.updateRTT(TimeoutPenalty * s.timeout)
}
}
In the code above rtt could be negative if time.Now() was earlier than start (which was set by a call to time.Now() earlier).
That code works well if time moves forward. Unfortunately, we’ve tuned our resolvers to be very fast which means that it’s normal for them to answer in a few milliseconds. If, right when a resolution is happening, time goes back a second the perceived resolution time will be negative.
RRDNS doesn’t just keep a single measurement for each resolver, it takes many measurements and smoothes them. So, the single measurement wouldn’t cause RRDNS to think the resolver was working in negative time, but after a few measurements the smoothed value would eventually become negative.
When RRDNS selects an upstream to resolve a CNAME it uses a weighted selection algorithm. The code takes the upstream time values and feeds them to Go’s rand.Int63n() function. rand.Int63n promptly panics if its argument is negative. That’s where the RRDNS panics were coming from.
(Aside: there are many other falsehoods programmers believe about time)
The one character fix
One precaution when using a non-monotonic clock source is to always check whether the difference between two timestamps is negative. Should this happen, it’s not possible to accurately determine the time difference until the clock stops rewinding.
In this patch we allowed RRDNS to forget about current upstream performance, and let it normalize again if time skipped backwards. This prevents leaking of negative numbers to the server selection code, which would result in throwing errors before attempting to contact the upstream server.

The fix we applied prevents the recording of negative values in server selection. Restarting all the RRDNS servers then fixed any recurrence of the problem.
Timeline
The following is the complete timeline of the events around the leap second bug.
2017-01-01 00:00 UTC Impact starts
2017-01-01 00:10 UTC Escalated to engineers
2017-01-01 00:34 UTC Issue confirmed
2017-01-01 00:55 UTC Mitigation deployed to one canary node and confirmed
2017-01-01 01:03 UTC Mitigation deployed to canary data center and confirmed
2017-01-01 01:23 UTC Fix deployed in most impacted data center
2017-01-01 01:45 UTC Fix being deployed to major data centers
2017-01-01 01:48 UTC Fix being deployed everywhere
2017-01-01 02:50 UTC Fix rolled out to most of the affected data centers
2017-01-01 06:45 UTC Impact ends
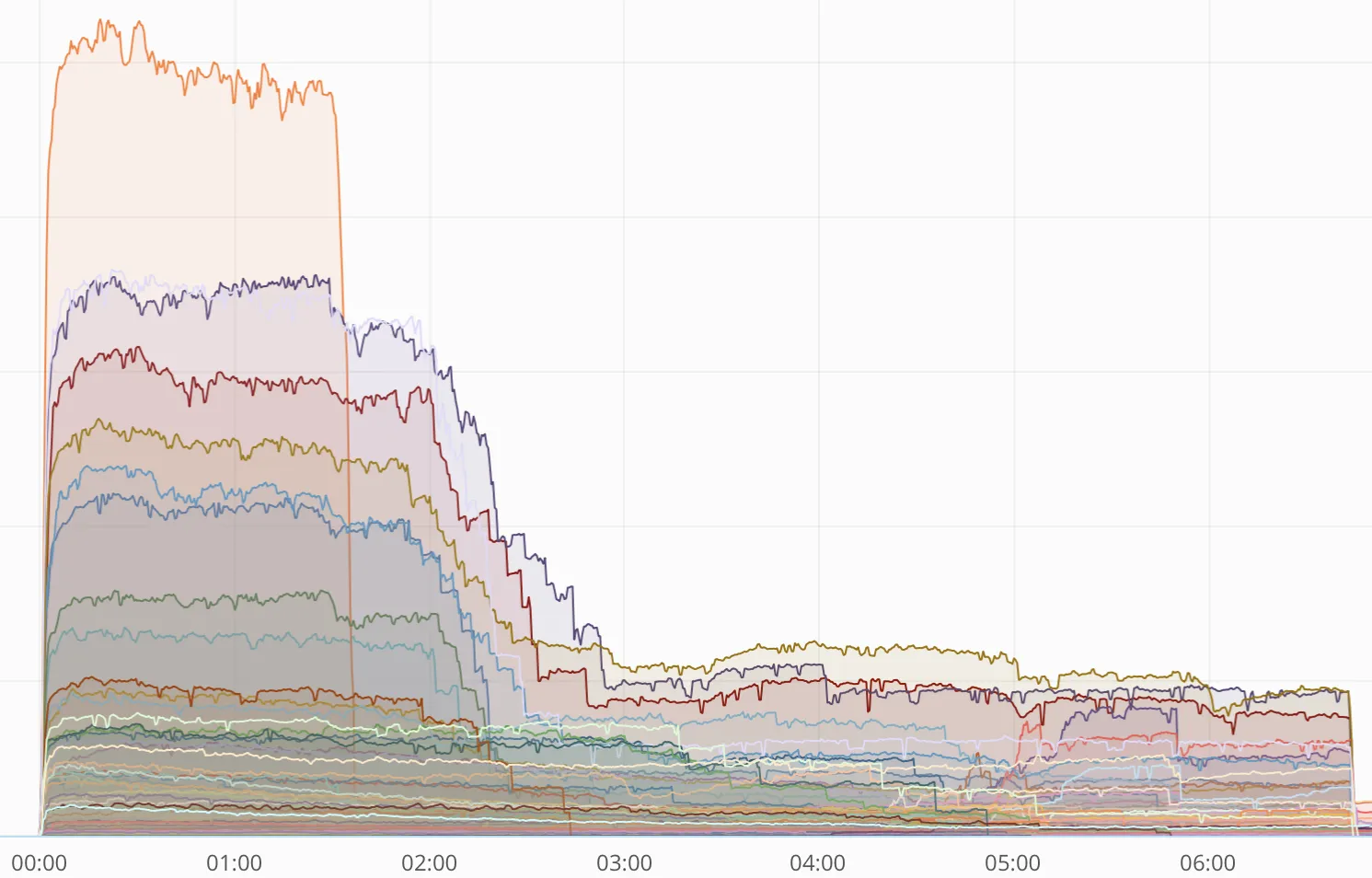
This chart shows error rates for each Cloudflare data center (some data centers were more affected than others) and the rapid drop in errors as the fix was deployed. We deployed the fix prioritizing those locations with the most errors first.
Conclusion
We are sorry that our customers were affected by this bug and are inspecting all our code to ensure that there are no other leap second sensitive uses of time intervals.
#reads #john cumming #cloudflare #rrdns #dns #leap second #time