The following article details how to implement a simple JVM from a design and Rust perspective.
https://andreabergia.com/blog/2023/07/i-have-written-a-jvm-in-rust/
Lately I’ve been spending quite a bit of time learning Rust, and as any sane person would do, after writing a few 100 lines programs I’ve decided to take on something a little bit more ambitious: I have written a Java Virtual Machine in Rust. 🎉 With a lot of originality, I have called it rjvm. The code is available on GitHub.
I want to stress that this is a toy JVM, built for learning purposes and not a serious implementation. In particular, it does not support:
- generics
- threads
- reflection
- annotations
- I/O
- just in time compiler
- string interning
However, there are quite a few non-trivial things implemented:
- control flow statements (
if, for, ...) - primitive and object creations
- virtual and static method invocation
- exceptions
- garbage collection
- class resolution from a
jarfile
For example, the following is part of the test suite:
class StackTracePrinting {
public static void main(String[] args) {
Throwable ex = new Exception();
StackTraceElement[] stackTrace = ex.getStackTrace();
for (StackTraceElement element : stackTrace) {
tempPrint(
element.getClassName() + "::" + element.getMethodName() + " - " +
element.getFileName() + ":" + element.getLineNumber());
}
}
// We use this in place of System.out.println because we don't have real I/O
private static native void tempPrint(String value);
}
It uses the real rt.jar containing the classes from the OpenJDK 7 - thus, in the example above, the java.lang.StackTraceElement class comes from a real JDK!
I am very happy with what I have learned, about Rust and about how to implement a virtual machine. In particular, I am super happy about having implemented a real, working, garbage collector. It’s quite mediocre, but it’s mine and I love it. 💘 Given that I have achieved what I set out to do originally, I have decided to stop the project here. I know there are bugs, but I do not plan to fix them.
Overview
In this post, I will give you an overview of how my JVM works. In further articles, I will go into more detail about some of the aspects discussed here.
Code organization
The code is a standard Rust project. I have split it into three crates (i.e. packages):
reader, which is able to read.classfiles and contains various types that model their content;vm, which contains the virtual machine that can execute the code as a library;vm_cli, which contains a very simple command-line launcher to run the VM, in the spirit of thejavaexecutable.
I’m considering extracting the reader crate in a separate repository and publishing it on crates.io, since it could actually be useful to someone else.
Parsing a .class file
As you know, Java is a compiled language - the javac compiler takes your .java source files and produces various .class files, generally distributed in a .jar file - which is just a zip. Thus, the first thing to do to execute some Java code is to load a .class file, containing the bytecode generated by the compiler. A class file contains various things:
- metadata about the class, such as its name or the source file name
- the superclass name
- the implemented interfaces
- the fields, along with their types and annotations
- and the methods with:
- their descriptor, which is a string representing the type of each parameter and the method’s return type
- metadata such as the
throwsclause, annotation, generics information - and the bytecode, along with some extra metadata such as the exception handler table and the line numbers table.
As mentioned above, for rjvm I have created a separate crate, named reader, which can parse a class file and return a Rust struct that models a class and all its content.
Executing methods
The main API of the vm crate is Vm::invoke, which is used to execute a method. It takes a CallStack, which will contain the various CallFrame, one for each method being executed. For executing main, the call stack will initially be empty, and a new frame will be created to run it. Then, each function invocation will add a new frame to the call stack. When a method’s execution completes, its corresponding frame will be dropped and removed from the call stack.
Most methods will be implemented in Java, and thus their bytecode will be executed. However, rjvm also supports native methods, i.e. methods that are implemented directly by the JVM and not in the Java bytecode. There are quite a few of them in the “lower parts” of the Java API, where interaction with the operating system (for example, to do I/O) or the support runtime is necessary. Some examples of the latter you might have seen include System::currentTimeMillis, System::arraycopy, or Throwable::fillInStackTrace. In rjvm, these are implemented by Rust functions.
The JVM is a stack-based virtual machine, i.e. the bytecode instructions operate mainly on a value stack. There is also a set of local variables, identified by an index, that can be used to store values and pass arguments to methods. These are associated with each call frame in rjvm.
Modeling values and objects
The type Value models a possible value of a local variable, stack element, or object’s field, and is implemented as follows:
/// Models a generic value that can be stored in a local variable or on the stack.
#[derive(Debug, Default, Clone, PartialEq)]
pub enum Value<'a> {
/// An unitialized element. Should never be on the stack,
/// but it is the default state for local variables.
#[default]
Uninitialized,
/// Models all the 32-or-lower-bits types in the jvm: `boolean`,
/// `byte`, `char`, `short`, and `int`.
Int(i32),
/// Models a `long` value.
Long(i64),
/// Models a `float` value.
Float(f32),
/// Models a `double` value.
Double(f64),
/// Models an object value
Object(AbstractObject<'a>),
/// Models a null object
Null,
}
As an aside, this is one place where a sum type, such as Rust’s enum, is a wonderful abstraction - it is great for expressing the fact that a value might be of multiple different types.
For storing objects and their values, I initially used a simple struct called Object containing a reference to the class (to model the object’s type) and a Vec<Value> for storing fields’ values. However, when I implemented the garbage collector, I modified this to use a lower-level implementation, with a ton of pointers and casts - quite C style! In the current implementation, an AbstractObject (which models a “real” object, or an array) is simply a pointer to an array of bytes, which contain a couple of header words and then the fields’ values.
Executing instructions
Executing a method means executing its bytecode instructions, one at a time. The JVM has a wide list of instructions (over two hundred!), encoded by one byte in the bytecode. Many instructions are followed by arguments, and some have a variable length. This is modeled in the code by the type Instruction:
/// Represents a Java bytecode instruction.
#[derive(Clone, Copy, Debug, Eq, PartialEq)]
pub enum Instruction {
Aaload,
Aastore,
Aconst_null,
Aload(u8),
// ...
The execution of a method will keep, as mentioned above, a stack and an array of local variables, referred by the instructions via their index. It will also initialize the program counter to zero - that is, the address of the next instruction to execute. The instruction will be processed and the program counter updated - generally advanced by one, but various jump instructions can move it to a different location. These are used to implement all flow control statements, such as if, for, or while.
A special family of instruction is made of those that can invoke another method. There are various ways of resolving which method should be invoked: virtual or static lookup are the main ones, but there are others. After resolving the correct instruction, rjvm will add a new frame to the call stack and start the method’s execution. The method’s return value will be pushed to the stack unless it is void, and execution will resume.
The Java bytecode format is quite interesting and I plan to dedicate a post to the various kind of instructions.
Exceptions
Exceptions are quite a complex beast to implement since they break the normal control flow, and might return early from a method (and propagate on the call stack!). I am pretty happy with the way I have implemented them, though, and I am going to show you some of the relevant code.
The first thing you need to know is that any catch block corresponds to an entry of a method’s exception table - each entry contains the range of covered program counters, the address for the first instruction in the catch block, and the exception’s class name which the block catches.
Next, the signature of CallFrame::execute_instruction is as follows:
fn execute_instruction(
&mut self,
vm: &mut Vm<'a>,
call_stack: &mut CallStack<'a>,
instruction: Instruction,
) -> Result<InstructionCompleted<'a>, MethodCallFailed<'a>>
Where the types are:
/// Possible execution result of an instruction
enum InstructionCompleted<'a> {
/// Indicates that the instruction executed was one of the return family. The caller
/// should stop the method execution and return the value.
ReturnFromMethod(Option<Value<'a>>),
/// Indicates that the instruction was not a return, and thus the execution should
/// resume from the instruction at the program counter.
ContinueMethodExecution,
}
/// Models the fact that a method execution has failed
pub enum MethodCallFailed<'a> {
InternalError(VmError),
ExceptionThrown(JavaException<'a>),
}
and the standard Rust Result type is:
enum Result<T, E> {
Ok(T),
Err(E),
}
Thus, executing an instruction can result in four possible states:
- the instruction was executed successfully, and the execution of the current method can continue (the standard case);
- the instruction was executed successfully, and it was a return instruction, thus the current method should return with (optionally) a return value;
- the instruction could not be executed, because some internal VM error happened;
- or the instruction could not be executed, because a standard Java exception was thrown.
The code that executes a method is thus as follows:
/// Executes the whole method
impl<'a> CallFrame<'a> {
pub fn execute(
&mut self,
vm: &mut Vm<'a>,
call_stack: &mut CallStack<'a>,
) -> MethodCallResult<'a> {
self.debug_start_execution();
loop {
let executed_instruction_pc = self.pc;
let (instruction, new_address) =
Instruction::parse(
self.code,
executed_instruction_pc.0.into_usize_safe()
).map_err(|_| MethodCallFailed::InternalError(
VmError::ValidationException)
)?;
self.debug_print_status(&instruction);
// Move pc to the next instruction, _before_ executing it,
// since we want a "goto" to override this
self.pc = ProgramCounter(new_address as u16);
let instruction_result =
self.execute_instruction(vm, call_stack, instruction);
match instruction_result {
Ok(ReturnFromMethod(return_value)) => return Ok(return_value),
Ok(ContinueMethodExecution) => { /* continue the loop */ }
Err(MethodCallFailed::InternalError(err)) => {
return Err(MethodCallFailed::InternalError(err))
}
Err(MethodCallFailed::ExceptionThrown(exception)) => {
let exception_handler = self.find_exception_handler(
vm,
call_stack,
executed_instruction_pc,
&exception,
);
match exception_handler {
Err(err) => return Err(err),
Ok(None) => {
// Bubble exception up to the caller
return Err(MethodCallFailed::ExceptionThrown(exception));
}
Ok(Some(catch_handler_pc)) => {
// Re-push exception on the stack and continue
// execution of this method from the catch handler
self.stack.push(Value::Object(exception.0))?;
self.pc = catch_handler_pc;
}
}
}
}
}
}
}
I know that there are quite a few implementation details in this code, but I hope it gives an idea of how using Rust’s Result and pattern matching maps really well to the description of the behavior above. I have to say I am rather proud of this code. 😊
Garbage collection
The final milestone in rjvm has been the implementation of the garbage collector. The algorithm I have chosen is a stop-the-world (which trivially follows from not having threads!) semispace copying collector. I have implemented a (poorer) variant of Cheney’s algorithm - but I really should go and implement the real thing… 😅
The idea is to split the available memory into two parts, called semispaces: one will be active and used to allocate objects, and the other will be unused. When full, a garbage collection will be triggered and all alive objects will be copied to the other semispace. Then, all references to objects will be updated, so that they point to the new copies. Finally, the role of the two will be swapped - similar to how blue-green deployment works.
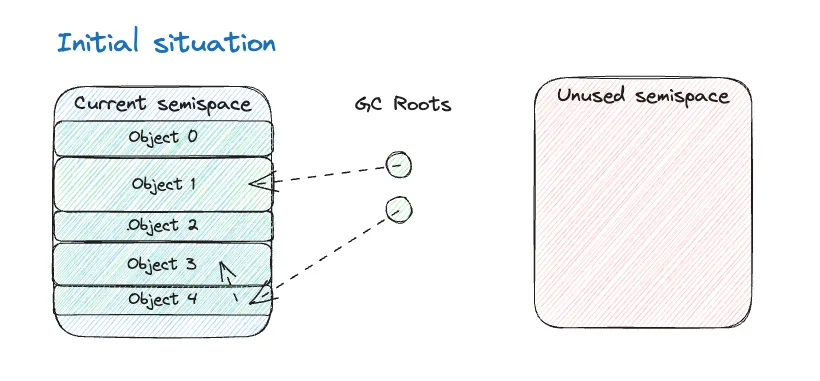
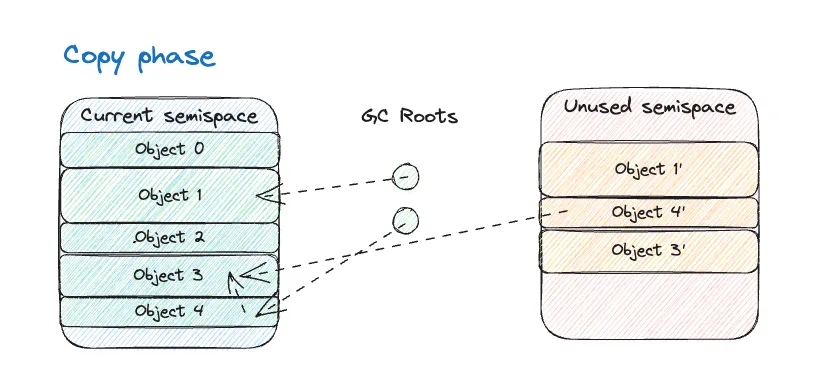
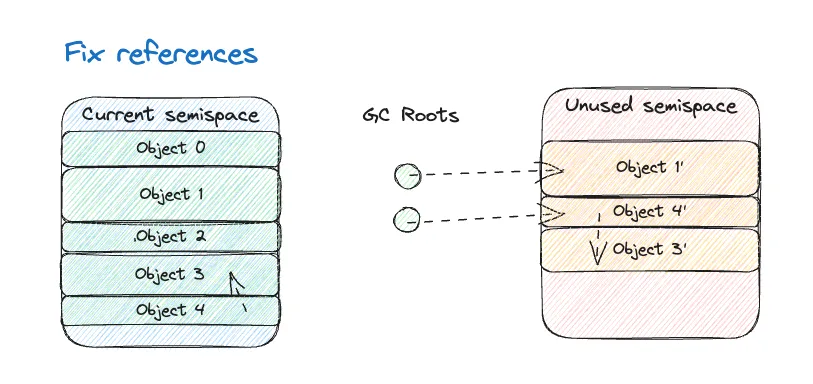
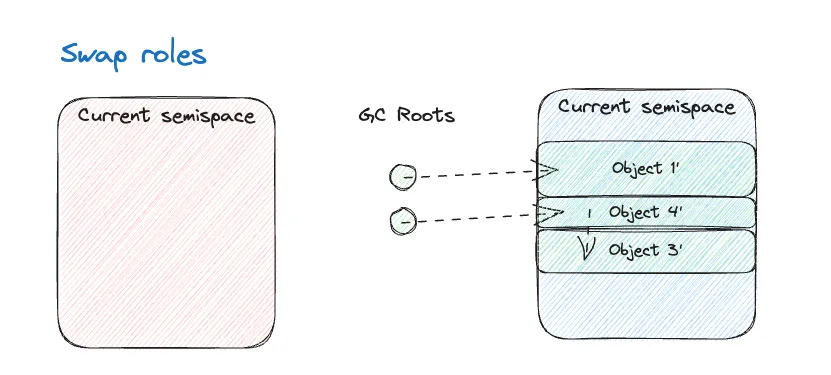
This algorithm has the following characteristics:
- obviously, it wastes a lot of memory (half of the possible max memory!);
- allocations are super fast (bumping a pointer);
- copying and compacting objects means that it does not have to deal with memory fragmentation;
- compacting objects can improve performances, due to better cache line utilization.
Real Java VMs use far more sophisticated algorithms, generally generational garbage collectors, such as G1 or the parallel GC, which use evolutions of the copying strategy.
Conclusions
In writing rjvm, I learned a lot and I had a lot of fun. Can’t ask for more from a side project… but maybe next time I will pick something a bit less ambitious to learn a new programming language! 🤭
As an aside, I want to say that I had a lot of fun with Rust. I think it is a great language, as I have written before, and I have really enjoyed using it for implementing my JVM!
If you are interested in further details on how rjvm is implemented (and on how the JVM actually works), stay tuned for the upcoming posts!