The following article explains the biggest disadvantages of using an ORM, rationalizing on why people bash it’s use or calling it an anti pattern.
https://github.com/getlago/lago/wiki/Is-ORM-still-an-%27anti-pattern%27%3F

Introduction
ORMs are one of those things that software writers like to pick on. There are many online articles that go by the same tune: “ORMs are an anti-pattern. They are a toy for startups, but eventually hurt more than help.”
This is an exaggeration. ORMs aren’t bad. Are they perfect? Definitely not, just like anything else in software. At the same time, the criticisms are expected—two years ago, I would’ve agreed with that stereotyped headline wholeheartedly. I’ve had my share of “What do you mean the ORM ran the server out of memory?” incidents.
But in reality, ORMs are more misused than overused.
Ironically, this “ORMs aren’t that bad” defense piece was inspired by a negative ORM incident we experienced at Lago that caused us to question our reliance on Active Record, the Ruby on Rails ORM. And a really tempting title for this post would’ve been “ORMs kinda suck”. But after some meditation on the matter, we’ve reasoned that ORMs do not suck. They are simply an abstraction with a quintessential pro and con—they abstract away some visibility and occasionally incur some performance hits. That’s about it.
Today, let’s dive into ORMs, their common criticisms, and the ones that are compelling in today’s context.
A Tale of Two Paradigms
Let’s start with an easy one: ORMs and databases follow two different paradigms.
ORMs produce objects. (Duh! That’s what the O stands for.) Objects are like directed graphs—nodes that point to other nodes but not necessarily to each other. Conversely, database relational tables contain data that are always linked bidirectionally via shared keys, aka an undirected graph.
Technically, ORMs can mimic undirected graphs by enforcing that pointers are bidirectional. Realistically, though, this isn’t trivial to set up; many developers end up with a User object missing its Posts array or the Posts array entities lacking a backreference to the same User object (but potentially a clone).
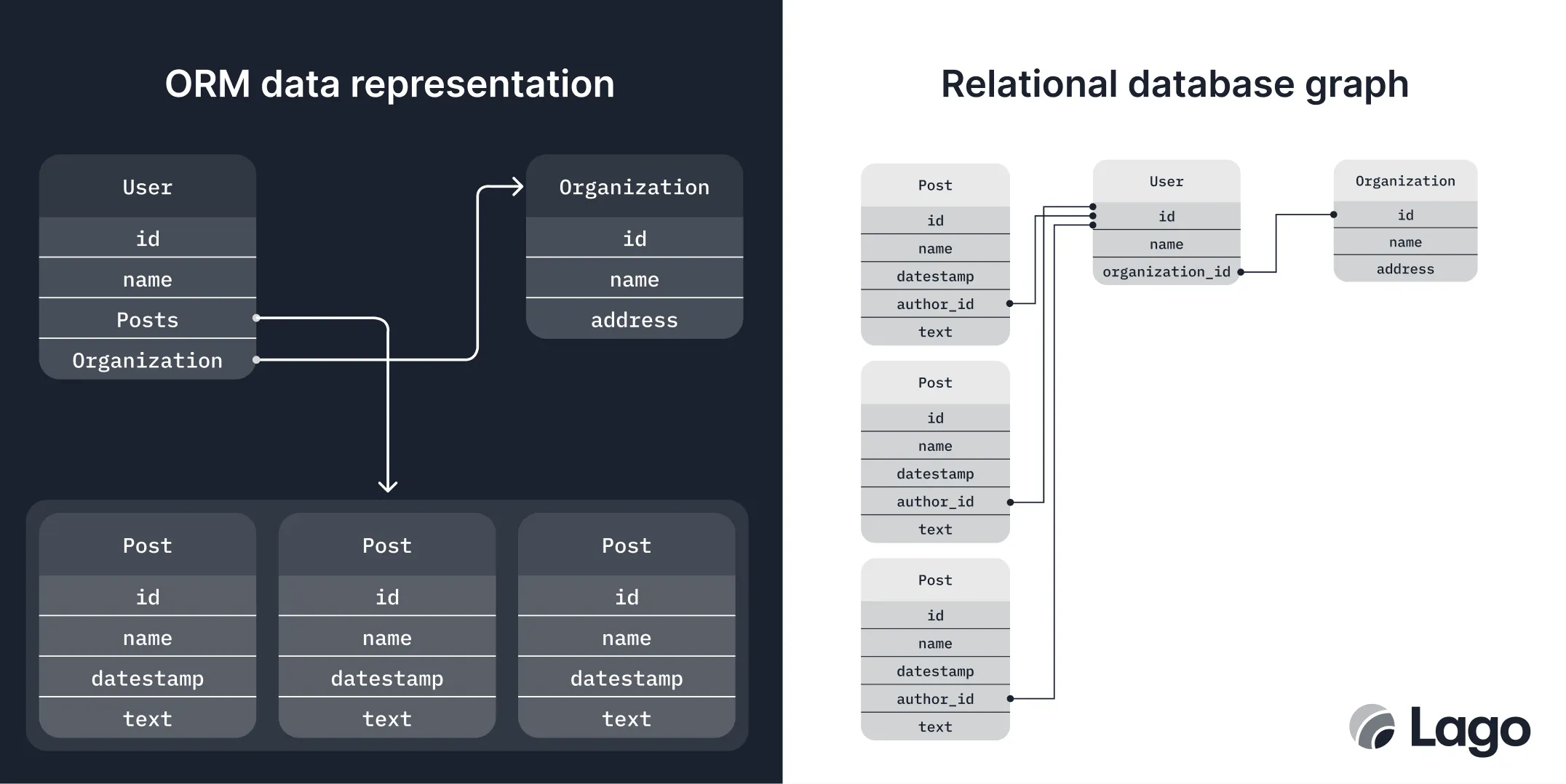
ORMs and relational databases operate under two different paradigms. For instance, an ORM might return a user’s posts as an array, but not include backreferences to the user (as Author) for each post.
This paradigm mismatch isn’t a be-all and end-all, however. ORMs and relational databases are still just graphs; just databases have exclusively nondirectional edges. While this is a good academic criticism of ORMs, the real issues with ORMs are a bit more “in the weeds”.
The broken principle(s)
Before diving into the aforementioned “weeds”, let’s touch on some more fundamental principles. A common complaint about ORMs is that they break two of the SOLID rules. If you aren’t familiar with SOLID, it is an acronym for the principles that are taught in college classes about software design.
SRP
ORMs violate SRP, the Society for Radiologi—sorry, the Single Responsibility Principle. SRP dictates that a class should exist for one purpose and one purpose only. And, well, ORMs don’t do that. Sure, at a high level, they do “all the database stuffs”, but that’s equivalent to creating a single class that does “all the app stuffs”. JohnoTheCoder explained it best: ORMs (i) create classes that transact with the database, (ii) represent a record, and (iii) define relationships. I would even toss in that ORMs (iv) create and execute migrations.
But if you’re eye-rolling at this semantic criticism, you’re not alone. I, too, believe this common argument against ORMs is very hand-wavy. After all, an ORM’s job is to bridge the gap between two fundamentally different data paradigms; of course it’ll break some principles.
SOC
Separation of Concerns, or SOC, is of similar spirit to SRP, but at the application layer. Separation of Concerns dictates that an infrastructure component should be concerned with one thing, not multiple. And an ORM shifts database management from the backend to the database, violating SOC. But SOC is a bit of a silly principle in today’s world. Nowadays, infrastructure components and coding patterns are combining tasks to achieve better performance (e.g., CPU aggregators within OLAP databases), lower latency (e.g., edge backend-frontends), and cleaner code (e.g., monorepos).
The real problems
Now that we’ve marathoned through the “fake” problem, let’s discuss the real problems with ORMs. ORMs play things safe. They use a predictable, repeatable query system that isn’t inherently optimized or visible. However, ORM developers are aware of this; they’ve added a ton of features that partially address these issues, making big strides since Active Record’s debut days.
Efficiency
A common criticism of ORMs is that they’re inefficient.
This is mostly false. ORMs are far more efficient than most programmers believe. However, ORMs encourage poor practices because of how easy it is to rely on host language logic (i.e., JavaScript or Ruby) to combine data.
For instance, take a look at this poorly optimized TypeORM code that uses JavaScript to expand data entries:
const authorRepository = connection.getRepository(Author);
const postRepository = connection.getRepository(Post);
// Fetch all authors who belong to a certain company
const authors = await authorRepository.find({ where: { company: 'Hooli' } });
// Loop through each author and update their posts separately
for (let i = 0; i < authors.length; i++) {
const posts = await postRepository.find({ where: { author: authors[i] } });
// Update each post separately
for (let j = 0; j < posts.length; j++) {
posts[j].status = 'archived';
await postRepository.save(posts[j]);
}
}
Instead, developers should use TypeORM’s built-in features that construct a single query:
const postRepository = connection.getRepository(Post);
await postRepository
.createQueryBuilder()
.update(Post)
.set({ status: 'archived' })
.where("authorId IN (SELECT id FROM author WHERE company = :company)", { company: 'Hooli' })
.execute();
A great example of this is the aforementioned Lago billing SQL refactor. Our issue with Active Record was visibility-related (discussed more in detail below). There was no performance difference between our ORM and raw SQL query analogs. Because we heavily used Active Record’s data union features, our query was optimized as is:
InvoiceSubscription
.joins('INNER JOIN subscriptions AS sub ON invoice_subscriptions.subscription_id = sub.id')
.joins('INNER JOIN customers AS cus ON sub.customer_id = cus.id')
.joins('INNER JOIN organizations AS org ON cus.organization_id = org.id')
.where("invoice_subscriptions.properties->>'timestamp' IS NOT NULL")
.where(
"DATE(#{Arel.sql(timestamp_condition)}) = DATE(#{today_shift_sql(customer: 'cus', organization: 'org')})",
today,
)
.recurring
.group(:subscription_id)
.select('invoice_subscriptions.subscription_id, COUNT(invoice_subscriptions.id) AS invoiced_count')
.to_sql
which was replaced by this raw SQL rewrite:
SELECT
invoice_subscriptions.subscription_id,
COUNT(invoice_subscriptions.id) AS invoiced_count
FROM invoice_subscriptions
INNER JOIN subscriptions AS sub ON invoice_subscriptions.subscription_id = sub.id
INNER JOIN customers AS cus ON sub.customer_id = cus.id
INNER JOIN organizations AS org ON cus.organization_id = org.id
WHERE invoice_subscriptions.recurring = 't'
AND invoice_subscriptions.properties->>'timestamp' IS NOT NULL
AND DATE(
(
-- TODO: A migration to unify type of the timestamp property must performed
CASE WHEN invoice_subscriptions.properties->>'timestamp' ~ '^[0-9.]+$'
THEN
-- Timestamp is stored as an integer
to_timestamp((invoice_subscriptions.properties->>'timestamp')::integer)::timestamptz
ELSE
-- Timestamp is stored as a string representing a datetime
(invoice_subscriptions.properties->>'timestamp')::timestamptz
END
)#{at_time_zone(customer: 'cus', organization: 'org')}
) = DATE(:today#{at_time_zone(customer: 'cus', organization: 'org')})
GROUP BY invoice_subscriptions.subscription_id
Now don’t get me wrong, ORMs are not as efficient as raw SQL queries. They are often a bit more inefficient, and in some choice cases, very inefficient.
The first issue is that ORMs sometimes incur massive computational overhead when converting queries into objects (TypeORM is a particular offender of this).
The second issue is that ORMs sometimes make multiple roundtrips to a database by looping through a one-to-many or many-to-many relationship. This is known as the N+1 problem (1 original query + N subqueries). For instance, the following Prisma query will make a new database request for every single comment!
{
users(take: 3) {
id
name
posts(take: 3) {
id
text
comments(take: 5) {
id
text
}
}
}
}
N + 1 is a common problem that ORMs struggle with. However, it can often be handled by using data loaders that collapse queries into two queries instead of N + 1. Accordingly, like most other common ORM “issues”, N+1 scenarios can often be avoided by fully leveraging an ORMs feature set.
Visibility
The biggest issue with ORMs is visibility. Because ORMs are effectively query writers, they aren’t the ultimate error dispatcher outside of obvious scenarios (such as incorrect primitive types). Rather, ORMs need to digest the returned SQL error and translate it to the user.
Active Record struggles with this, and that’s why we refactored our billing subscription query. Whenever we got results we didn’t expect, we’d have to inspect the rendered SQL query, rerun it, and then translate the SQL error into Active Record changes. This back-and-forth process undermined the original purpose of using Active Record, which was to avoid interfacing directly with the SQL database.
Closing thoughts
ORMs aren’t a bad thing. When leveraged correctly, they could be nearly as efficient as raw SQL. Unfortunately, ORMs are often incorrectly leveraged. Developers might rely too much on host language logic structures to create data structures and not enough on the ORMs’ native SQL analog features.
However, ORMs do falter on visibility and debugging—which is exactly what we faced at Lago. When a large query is giving developers trouble, shifting it to a raw SQL query may be a good investment. Thankfully, most ORMs allow you to execute a SQL query from within the ORM itself.