The following article provides a step by step walk through to implement LLaMA (“foundational large language model” by Meta AI) in Python solely using the paper. The official paper can be found here: https://arxiv.org/pdf/2302.13971.pdf
https://blog.briankitano.com/llama-from-scratch/
I want to provide some tips from my experience implementing a paper. I’m going to cover implementing a dramatically scaled-down version of Llama for training TinyShakespeare. This post is heavily inspired by Karpathy’s Makemore series, which I highly recommend.
A preview of what we’re going to end up with:
print(generate(llama, MASTER_CONFIG, 500)[0])
Evend her break of thou thire xoing dieble had side, did foesors exenatedH in siffied up, No, none, And you ling as thought depond.
MENENIUS:
Tell officien:
To pesiding be
Best wanty and to spiege,
To uncine shee patss again,
I will hen: then they
Moieth:
I my cast in letch:
For bereful, give toan I may
LINT OF AUMERLE:
Out, or me but thee here sir,
Why first with canse pring;
Now!
Gide me couuse
The haster:
And suilt harming,
Then as pereise with and go.
FROMNIUS:
I well? speak and wieke ac
I’ll be skipping over some of the more obvious steps, like setting up a virtual environment and installing dependencies.
Github here.
tl;dr 👓
Always work iteratively: start small, stay certain, and build up.
My approach for implementing papers is:
- Make all of the helper functions required to test your model quantitatively (data splits, training, plotting the loss).
- Before you even look at the paper, pick a small, simple, and fast model that you’ve done in the past. Then make a helper function to evaluate the model qualitatively.
- Start by picking apart different components of the paper, and then implementing them one-by-one, training and evaluating as you go.
Make sure your layers do what you think.
- Use
.shapereligiously.assertandplt.imshoware your friends. - Work out the results without matrix multiplication first, and then use the
torchfunctions to make it efficient after. - Have a test to see that your layer is right. For example, the RoPE embeddings have a specific property that you can test for. For the Transformer, you can test that the attention is working by looking at the attention map.
- Test your layers on various batch, sequence, and embedding sizes. Even if it works for one size, it might not work for others, which will cause problems at inference time.
Let’s go 👉
About Llama
Llama is a transformer-based model for language modeling. Meta AI open-sourced Llama this summer, and it’s gained a lot of attention (pun intended). When you’re reading the introduction, they clearly indicate their goal: make a model that’s cheaper for running inference, rather than optimizing training costs.
At this point, we’ll just load our libraries and get started.
import torch
from torch import nn
from torch.nn import functional as F
import numpy as np
from matplotlib import pyplot as plt
import time
import pandas as pd
Setting up our dataset
While in Llama they train on 1.4T tokens, our dataset TinyShakespeare, the collection of all of Shakespeare’s works, is about 1M characters.
lines = open('./input.txt', 'r').read()
vocab = sorted(list(set(lines)))
itos = {i:ch for i, ch in enumerate(vocab)}
stoi = {ch:i for i, ch in enumerate(vocab)}
print(lines[:30])
First Citizen:
Before we proce
They use the SentencePiece byte-pair encoding tokenizer, but we’re going to just use a simple character-level tokenizer.
# simple tokenization by characters
def encode(s):
return [stoi[ch] for ch in s]
def decode(l):
return ''.join([itos[i] for i in l])
print('vocab size:', len(vocab))
decode(encode("hello"))
vocab size: 65
'hello'
Since our dataset is small enough, we don’t need to worry about how we store it in memory etc.
First tip: I’m creating a config object that stores some basic model params. It makes our code way more readable and removes constants and magic numbers from the code. I’m not going to use types, as I want to keep things flexible for now and be able to add more parameters later on.
MASTER_CONFIG = {
"vocab_size": len(vocab),
}
dataset = torch.tensor(encode(lines), dtype=torch.int8)
dataset.shape
torch.Size([1115394])
Let’s create a method to generate our training data and labels for batches. We’ll use the same method for validation and test data. Note that I like to test my functions in the same block that I define them, just to make sure they work as expected before moving on.
def get_batches(data, split, batch_size, context_window, config=MASTER_CONFIG):
train = data[:int(.8 * len(data))]
val = data[int(.8 * len(data)): int(.9 * len(data))]
test = data[int(.9 * len(data)):]
batch_data = train
if split == 'val':
batch_data = val
if split == 'test':
batch_data = test
# pick random starting points
ix = torch.randint(0, batch_data.size(0) - context_window - 1, (batch_size,))
x = torch.stack([batch_data[i:i+context_window] for i in ix]).long()
y = torch.stack([batch_data[i+1:i+context_window+1] for i in ix]).long()
return x, y
MASTER_CONFIG.update({
'batch_size': 32,
'context_window': 16
})
xs, ys = get_batches(dataset, 'train', MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'])
[(decode(xs[i].tolist()), decode(ys[i].tolist())) for i in range(len(xs))]
[('t us sup betimes', ' us sup betimes,'),
('IO:nRight.nnROME', 'O:nRight.nnROMEO'),
('Nurse:nO, she sa', 'urse:nO, she say'),
(" seem'd to know,", "seem'd to know,n"),
(' let her brother', 'let her brother '),
('ood,nEven with s', 'od,nEven with su'),
('ennWhisper the s', 'nnWhisper the sp'),
(', fly! for all y', ' fly! for all yo'),
(" Saint Peter's C", "Saint Peter's Ch"),
(', but thatnWhich', ' but thatnWhich '),
('uld as willingly', 'ld as willingly '),
('y brother,nIs pr', ' brother,nIs pri'),
(' you ready your ', 'you ready your s'),
('rth the audience', 'th the audience '),
('nnQUEEN ELIZABET', 'nQUEEN ELIZABETH'),
('ection,nwhich ca', 'ction,nwhich can'),
('is wisdom hastes', 's wisdom hastes '),
(' and quinces in ', 'and quinces in t'),
('nt death.nnSICIN', 't death.nnSICINI'),
("y she's mad.nnBR", " she's mad.nnBRU"),
('eware of him;nSi', 'ware of him;nSin'),
('snAnd make pursu', 'nAnd make pursui'),
('r and be slain; ', ' and be slain; n'),
(' I, with grief a', 'I, with grief an'),
('?nnSecond Keeper', 'nnSecond Keeper:'),
('nNow, Thomas Mow', 'Now, Thomas Mowb'),
('or this once, ye', 'r this once, yea'),
("l 'tis just.nnLU", " 'tis just.nnLUC"),
('es like a lamb. ', 's like a lamb. Y'),
('t night, I warra', ' night, I warran'),
('y tears would wa', ' tears would was'),
('nnANGELO:nWell, ', 'nANGELO:nWell, l')]
What’s interesting about implementing papers is that there are two aspects to the model working: compilation (do your tensors all match up from layer to layer), and training (does the loss go down). Figuring out how to ensure that each of your components is working is key to developing your model in a predictable, engineering-minded way.
That’s why we’re also going to define the method for how we’re going to evaluate the model. We want to do this before we even define the model, because we want to be able to use it to evaluate the model as we’re training it.
@torch.no_grad() # don't compute gradients for this function
def evaluate_loss(model, config=MASTER_CONFIG):
out = {}
model.eval()
for split in ["train", "val"]:
losses = []
for _ in range(10):
xb, yb = get_batches(dataset, split, config['batch_size'], config['context_window'])
_, loss = model(xb, yb)
losses.append(loss.item())
out[split] = np.mean(losses)
model.train()
return out
Setting up a working base model
Here’s a basic feed-forward neural network with embeddings. It’s the base model we’re going to start with, and then swap out parts of it as we go along until we eventually end up with the model as described in Llama.
class SimpleBrokenModel(nn.Module):
def __init__(self, config=MASTER_CONFIG):
super().__init__()
self.config = config
self.embedding = nn.Embedding(config['vocab_size'], config['d_model'])
self.linear = nn.Sequential(
nn.Linear(config['d_model'], config['d_model']),
nn.ReLU(),
nn.Linear(config['d_model'], config['vocab_size']),
)
print("model params:", sum([m.numel() for m in self.parameters()]))
def forward(self, idx, targets=None):
x = self.embedding(idx)
a = self.linear(x)
logits = F.softmax(a, dim=-1)
if targets is not None:
loss = F.cross_entropy(logits.view(-1, self.config['vocab_size']), targets.view(-1))
return logits, loss
else:
return logits
MASTER_CONFIG.update({
'd_model': 128,
})
model = SimpleBrokenModel(MASTER_CONFIG)
xs, ys = get_batches(dataset, 'train', MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'])
logits, loss = model(xs, ys)
model params: 33217
It’s at this point that we have to start worrying about the shape of our tensors and making indices match. Check out this line of our model definition:
loss = F.cross_entropy(logits.view(-1, config['vocab_size']), targets.view(-1))
We have to reshape the logits and targets tensors so that their dimensions match when we compare. We do this with the view method. The -1 argument means “infer this dimension from the others”. So, in this case, we’re saying “reshape logits and targets to have the same number of rows, and however many columns are needed to make that happen”. This is a common pattern when you’re working with batches of data.
Alright, let’s train our SimpleBrokenModel to make sure gradients flow. After we confirm that, we can swap out parts of it to match Llama, train again, and track our progress. It’s at this point that I start keeping a log of my training runs, so that I can easily just go back to a previous run in the event that I mess something up.
MASTER_CONFIG.update({
'epochs': 1000,
'log_interval': 10
})
model = SimpleBrokenModel(MASTER_CONFIG)
optimizer = torch.optim.Adam(
model.parameters(),
)
def train(model, optimizer, scheduler=None, config=MASTER_CONFIG, print_logs=False):
losses = []
start_time = time.time()
for epoch in range(config['epochs']):
optimizer.zero_grad()
xs, ys = get_batches(dataset, 'train', config['batch_size'], config['context_window'])
logits, loss = model(xs, targets=ys)
loss.backward()
optimizer.step()
if scheduler:
scheduler.step()
if epoch % config['log_interval'] == 0:
batch_time = time.time() - start_time
x = evaluate_loss(model)
losses += [x]
if print_logs:
print(f"Epoch {epoch} | val loss {x['val']:.3f} | Time {batch_time:.3f} | ETA in seconds {batch_time * (config['epochs'] - epoch)/config['log_interval'] :.3f}")
start_time = time.time()
if scheduler:
print("lr: ", scheduler.get_lr())
print("validation loss: ", losses[-1]['val'])
return pd.DataFrame(losses).plot()
train(model, optimizer)
model params: 33217
validation loss: 3.9457355260849
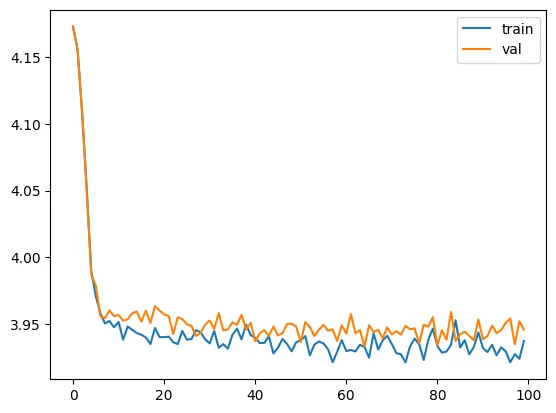
Notice how we get a training curve that goes down, but barely by anything. How do we know it’s barely training? We have to use first principles. The cross-entropy loss before training is 4.17, and after 1000 epochs is 3.93. How can we make sense of it intuitively?
Cross-entropy in this context is referring to how likely we are to pick the wrong word. So here,
H(T,q)=−∑i=1N1Nlogq(xi)
where $q(x_i)$ is the probability of picking the right word, as estimated by the model. If $q(x_i)$ is close to 1, then $log q$ is close to 0; similarly, if $q$ is small, then $log q$ is a large negative number, so $-log q$ will be a large positive number. Now to build the intuition: to start, $-log q = 4.17$, so $q = 0.015$, or around $frac{1}{64.715}$. Recall that the vocabulary size $|V| = 65$, so what we’re basically saying here is that the model is as good at choosing the next letter as randomly picking from our vocabulary. After training, $-log q = 3.93$, so we’re now basically choosing between 50 letters. This is a very small improvement, so something is probably wrong.
To get an intuition for how the loss relates to the model’s performance, think about the model choosing among $tilde V$ tokens; when $tilde V$ is small, the model is more likely to guess right. In addition, we know $max tilde V = V$, which can help us understand if our model is learning at all.
V~=exp(L)
Let’s try to debug what’s going on. Notice that in our model we’re using a softmax layer on our logits, which is a function that takes a vector of numbers and squashes them into a probability distribution. But for using the built in F.cross_entropy function, we need to pass in the unnormalized logits directly. So let’s remove that from our model and try again.
class SimpleModel(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.embedding = nn.Embedding(config['vocab_size'], config['d_model'])
self.linear = nn.Sequential(
nn.Linear(config['d_model'], config['d_model']),
nn.ReLU(),
nn.Linear(config['d_model'], config['vocab_size']),
)
print("model params:", sum([m.numel() for m in self.parameters()]))
def forward(self, idx, targets=None):
x = self.embedding(idx)
logits = self.linear(x)
if targets is not None:
loss = F.cross_entropy(logits.view(-1, self.config['vocab_size']), targets.view(-1))
return logits, loss
else:
return logits
model = SimpleModel(MASTER_CONFIG)
xs, ys = get_batches(dataset, 'train', MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'])
logits, loss = model(xs, ys)
optimizer = torch.optim.Adam(model.parameters())
train(model, optimizer)
model params: 33217
validation loss: 2.5113263607025145
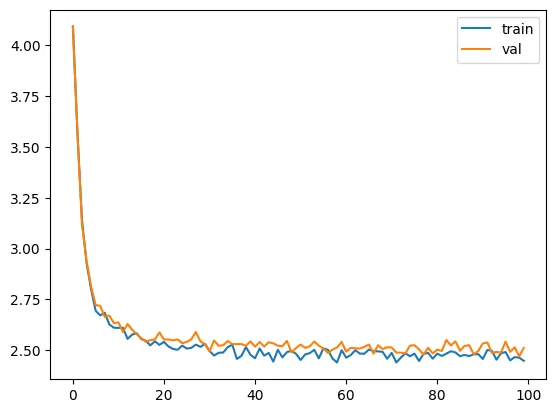
Great, now our loss is $2.54$, so we’re choosing from $12.67$ characters. That’s way better than the 65 we started with. Let’s add a generate method to our model so we visually see the results of our model.
def generate(model, config=MASTER_CONFIG, max_new_tokens=30):
idx = torch.zeros(5, 1).long()
for _ in range(max_new_tokens):
# call the model
logits = model(idx[:, -config['context_window']:])
last_time_step_logits = logits[
:, -1, :
] # all the batches (1), last time step, all the logits
p = F.softmax(last_time_step_logits, dim=-1) # softmax to get probabilities
idx_next = torch.multinomial(
p, num_samples=1
) # sample from the distribution to get the next token
idx = torch.cat([idx, idx_next], dim=-1) # append to the sequence
return [decode(x) for x in idx.tolist()]
generate(model)
['nWI innThed grtendnA yod ys wit',
'nY aroticunutsernE oy mendomed ',
"nnRIf t fan f ses, k be wn'd mo",
'nRu hiseedst den t wat onderyou',
"nARaceps hond wr fnI' fu kn be "]
It’s not half bad, but also not half good. But now we have a working model that is training to a validation loss. So here we’ll iterate on our model to make it closer to Llama.
Llama specifics
Llama describes three architectural modifications to the original Transformer:
- RMSNorm for pre-normalization
- Rotary embeddings
- SwiGLU activation function
We’re going to add each one, one at a time to our base model, and iterate.
RMSNorm
In Vaswani 2017, the original transformer uses BatchNormalization. In Llama, the authors use RMSNorm, which is where you scale the bector by the variance without centering it. In addition, while Vaswani applies normalization to the output of the attention layer (post-normalization), Llama applies it to the inputs before (pre-normalization).
class RMSNorm(nn.Module):
def __init__(self, layer_shape, eps=1e-8, bias=False):
super(RMSNorm, self).__init__()
self.register_parameter("scale", nn.Parameter(torch.ones(layer_shape)))
def forward(self, x):
"""
assumes shape is (batch, seq_len, d_model)
"""
# frob norm is not the same as RMS. RMS = 1/sqrt(N) * frob norm
ff_rms = torch.linalg.norm(x, dim=(1,2)) * x[0].numel() ** -.5
raw = x / ff_rms.unsqueeze(-1).unsqueeze(-1)
return self.scale[:x.shape[1], :].unsqueeze(0) * raw
config = {
'batch_size': 5,
'context_window': 11,
'd_model': 13,
}
batch = torch.randn((config['batch_size'], config['context_window'], config['d_model']))
m = RMSNorm((config['context_window'], config['d_model']))
g = m(batch)
print(g.shape)
torch.Size([5, 11, 13])
We want to test to ensure that the RMSNorm is doing what we think it should. We can do this the old-fashioned way: row-wise comparisons. The RMSNorm has the property where the norm of the layer will be the square root of the number of elements in the layer, so we can check that for every layer.
rms = torch.linalg.norm(batch, dim=(1,2)) * (batch[0].numel() ** -.5)
# scaled_batch.var(dim=(1,2))
assert torch.linalg.norm( torch.arange(5).float() ) == (torch.arange(5).float() ** 2 ).sum() ** .5
rms = torch.linalg.norm( torch.arange(5).float() ) * (torch.arange(5).numel() ** -.5)
assert torch.allclose(torch.linalg.norm(torch.arange(5).float() / rms), torch.tensor(5 ** .5))
ff_rms = torch.linalg.norm(batch, dim=(1,2)) * batch.shape[1:].numel() ** -.5
# RMS for sure
ffx = torch.zeros_like(batch)
for i in range(batch.shape[0]):
ffx[i] = batch[i] / ff_rms[i]
assert torch.allclose(torch.linalg.norm(ffx, dim=(1,2)) ** 2, torch.tensor(143).float())
assert torch.allclose(ffx, g)
Alright, so that’s RMSNorm, and it seems like it’s working. Again, let’s test it out.
class SimpleModel_RMS(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.embedding = nn.Embedding(config['vocab_size'], config['d_model'])
self.rms = RMSNorm((config['context_window'], config['d_model']))
self.linear = nn.Sequential(
nn.Linear(config['d_model'], config['d_model']),
nn.ReLU(),
nn.Linear(config['d_model'], config['vocab_size']),
)
print("model params:", sum([m.numel() for m in self.parameters()]))
def forward(self, idx, targets=None):
x = self.embedding(idx)
x = self.rms(x) # rms pre-normalization
logits = self.linear(x)
if targets is not None:
loss = F.cross_entropy(logits.view(-1, self.config['vocab_size']), targets.view(-1))
return logits, loss
else:
return logits
model = SimpleModel_RMS(MASTER_CONFIG)
xs, ys = get_batches(dataset, 'train', MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'])
logits, loss = model(xs, ys)
optimizer = torch.optim.Adam(model.parameters())
train(model, optimizer)
model params: 35265
validation loss: 2.4792869329452514
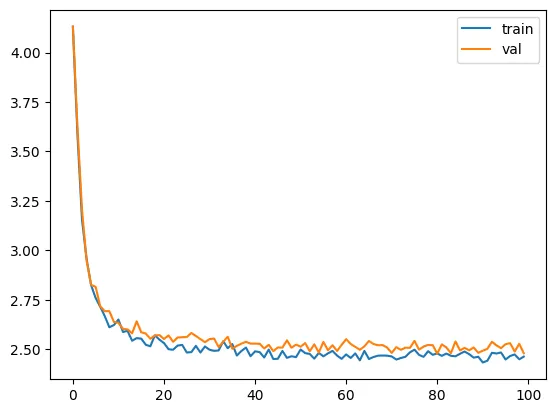
So RMSNorm works, and it got our loss down by a small amount.
Rotary Embeddings
RoPE is a kind of positional encoding for transformers. In Attention is All You Need, the authors propose two kinds of positional encodings, learned and fixed. In RoPE, the authors propose embedding the position of a token in a sequence by rotating the embedding, with a different rotation at each position.
def get_rotary_matrix(context_window, embedding_dim):
R = torch.zeros((context_window, embedding_dim, embedding_dim), requires_grad=False)
for position in range(context_window):
for i in range(embedding_dim//2):
theta = 10000. ** (-2.*(i - 1) / embedding_dim)
m_theta = position * theta
R[position, 2*i,2*i] = np.cos(m_theta)
R[position, 2*i,2*i+1] = - np.sin(m_theta)
R[position, 2*i+1,2*i] = np.sin(m_theta)
R[position, 2*i+1,2*i+1] = np.cos(m_theta)
return R
K = 3
config = {
'batch_size': 10,
'd_model': 32,
'n_heads': 8,
'context_window': K**2,
}
batch = torch.randn(1, config['context_window'], config['d_model'])
R = get_rotary_matrix(config['context_window'], config['d_model'])
fig, ax = plt.subplots(K, K, figsize=(K * 3, K * 4))
for i in range(K):
for j in range(K):
ax[i, j].imshow(R[i * K + j, :, :].detach().numpy())
ax[i, j].set_title(f'rotation at {i * K + j}')
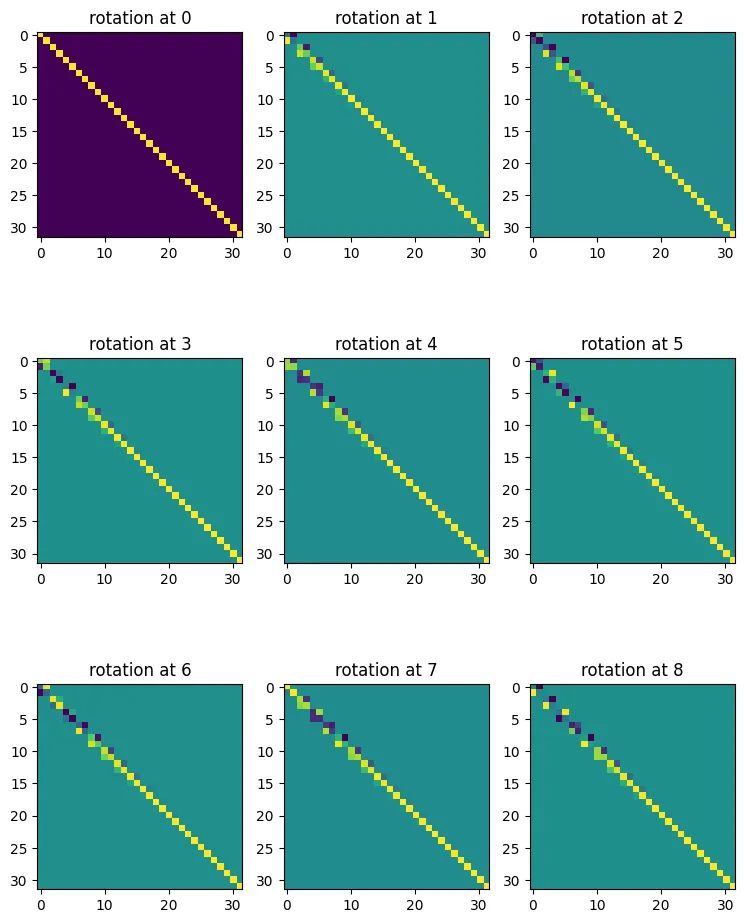
Let’s make sure these work. They should exhibit the quality that qmTkn=(RΘ,mdWqxm)T(RΘ,ndWkxn)=xTWqRΘ,n−mdWkxn.
config = {
'd_model': 128,
'context_window': 16,
}
R = get_rotary_matrix(config['context_window'], config['d_model'])
x = torch.randn(config['d_model'])
y = torch.randn(config['d_model'])
m = 3
n = 13
x_m = R[m,:,:] @ x
x_n = R[n,:,:] @ y
assert torch.isclose(x_m @ x_n, x @ R[n-m,:,:] @ y)
So the RoPE rotations work as expected.
config = {
'batch_size': 10,
'd_model': 512,
'n_heads': 8,
'context_window': 16,
}
class RoPEAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.w_q = nn.Linear(config['d_model'], config['d_model'], bias=False)
self.w_k = nn.Linear(config['d_model'], config['d_model'], bias=False)
self.w_v = nn.Linear(config['d_model'], config['d_model'], bias=False)
self.multihead = nn.MultiheadAttention(config['d_model'], config['n_heads'], dropout=0.1, batch_first=True)
self.R = get_rotary_matrix(config['context_window'], config['d_model'])
def get_rotary_matrix(context_window, embedding_dim):
R = torch.zeros((context_window, embedding_dim, embedding_dim), requires_grad=False)
for position in range(context_window):
for i in range(embedding_dim//2):
theta = 10000. ** (-2.*(i - 1) / embedding_dim)
m_theta = position * theta
R[position, 2*i,2*i] = np.cos(m_theta)
R[position, 2*i,2*i+1] = - np.sin(m_theta)
R[position, 2*i+1,2*i] = np.sin(m_theta)
R[position, 2*i+1,2*i+1] = np.cos(m_theta)
return R
def forward(self, x, return_attn_weights=False):
b,m,d = x.shape
q = self.w_q(x)
k = self.w_k(x)
v = self.w_v(x)
q_out = (torch.bmm(q.transpose(0,1), self.R)).transpose(0,1)
k_out = (torch.bmm(k.transpose(0,1), self.R)).transpose(0,1)
v_out = (torch.bmm(v.transpose(0,1), self.R)).transpose(0,1)
activations, attn_weights = self.multihead(
q_out,k_out,v_out,
)
if return_attn_weights:
return activations, attn_weights
return activations
layer = RoPEAttention(config)
batch = torch.randn((config['batch_size'], config['context_window'], config['d_model']))
output, attn_weights = layer(batch, return_attn_weights=True)
Tip here: know the difference between tensor dimensions at train time vs tensor dimensions at inference time.
Although at train time, you can expect your tensor dimensions to match your model parameters closely, eg batch.shape = (config['batch_size'], config['context_window'], config['d_model']), at inference time, you may have to deal with a single example, eg batch.shape = (1, 1, config['d_model']). For this reason, you need to make sure that when you’re indexing in the forward pass, you’re indexing using shapes derived from the input, not necessarily the model parameters.
Let’s make sure it does what we think it does. For this layer, we’re going to want to test three things:
that it rotates embeddings the way we think it does
that the attention mask used for causal attention is working properly.
x = torch.randn((config['batch_size'], config['context_window'], config['d_model'])) q = layer.w_q(x) k = layer.w_k(x) v = layer.w_v(x) q_rotated = torch.zeros_like(x) k_rotated = torch.zeros_like(x) v_rotated = torch.zeros_like(x) for position in range(config['context_window']): q_rotated[:,position,:] = torch.matmul(q[:,position,:], layer.R[position,:,:]) k_rotated[:,position,:] = torch.matmul(k[:,position,:], layer.R[position,:,:]) v_rotated[:,position,:] = torch.matmul(v[:,position,:], layer.R[position,:,:]) q_out = (torch.bmm(q.transpose(0,1), layer.R)).transpose(0,1) k_out = (torch.bmm(k.transpose(0,1), layer.R)).transpose(0,1) v_out = (torch.bmm(v.transpose(0,1), layer.R)).transpose(0,1) assert torch.allclose(q.transpose(0,1)[0], q[:,0,:]) assert torch.allclose(q.transpose(0,1)[0] @ layer.R[0], q[:,0,:] @ layer.R[0]) assert torch.allclose(q_rotated, q_out) config = { 'batch_size': 1, 'd_model': 2, 'n_heads': 2, 'context_window': 3, } layer = RoPEAttention(config) batch = torch.ones((config['batch_size'], config['context_window'], config['d_model'])) output, attn_weights = layer(batch, return_attn_weights=True) m = 0 x_q = batch[0, m] q = layer.R[m,:,:] @ layer.w_q(x_q) assert torch.allclose(layer.w_q(x_q), layer.w_q.weight @ x_q) assert torch.allclose(q, layer.R[m, :, :] @ layer.w_q.weight @ x_q) n = 2 x_k = batch[0, n] k = layer.R[n,:,:] @ layer.w_k(x_k) assert torch.allclose(layer.w_k(x_k), layer.w_k.weight @ x_k) assert torch.allclose(k, layer.R[n, :, :] @ layer.w_k.weight @ x_k) assert q.T @ k == q @ k # transpose is redundant assert torch.allclose(q @ k, x_k.T @ layer.w_k.weight.T @ layer.R[n, :, :].T @ layer.R[m, :, :] @ layer.w_q.weight @ x_q) assert torch.allclose(q @ k, x_k.T @ layer.w_k.weight.T @ layer.R[n-m, :, :].T @ layer.w_q.weight @ x_q) /var/folders/w4/2j887mvs097bkhhjpgfzjlyr0000gn/T/ipykernel_17478/2550954139.py:26: UserWarning: The use of `x.T` on tensors of dimension other than 2 to reverse their shape is deprecated and it will throw an error in a future release. Consider `x.mT` to transpose batches of matrices or `x.permute(*torch.arange(x.ndim - 1, -1, -1))` to reverse the dimensions of a tensor. (Triggered internally at /Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/native/TensorShape.cpp:3575.) assert q.T @ k == q @ k # transpose is redundant
Now let’s inspect the attention weights. Since this is causal, we would expect that due to masking, the upper triangular of the attention should be 0.
MASTER_CONFIG.update({
'n_heads': 8,
})
layer = RoPEAttention(MASTER_CONFIG)
batch = torch.ones((MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'], MASTER_CONFIG['d_model']))
output, attn_weights = layer(batch, return_attn_weights=True)
plt.imshow(attn_weights[0].detach().numpy(), interpolation='nearest')
plt.colorbar()
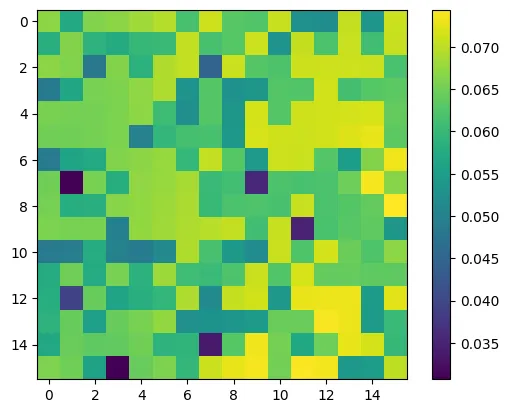
This is not good; it means that information is leaking across the attention. We need to ensure the causal mask is working.
class RoPEAttention_wMask(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.w_q = nn.Linear(config['d_model'], config['d_model'], bias=False)
self.w_k = nn.Linear(config['d_model'], config['d_model'], bias=False)
self.w_v = nn.Linear(config['d_model'], config['d_model'], bias=False)
self.multihead = nn.MultiheadAttention(config['d_model'], config['n_heads'], dropout=0.1, batch_first=True)
self.R = get_rotary_matrix(config['context_window'], config['d_model'])
def get_rotary_matrix(context_window, embedding_dim):
R = torch.zeros((context_window, embedding_dim, embedding_dim), requires_grad=False)
for position in range(context_window):
for i in range(embedding_dim//2):
theta = 10000. ** (-2.*(i - 1) / embedding_dim)
m_theta = position * theta
R[position, 2*i,2*i] = np.cos(m_theta)
R[position, 2*i,2*i+1] = - np.sin(m_theta)
R[position, 2*i+1,2*i] = np.sin(m_theta)
R[position, 2*i+1,2*i+1] = np.cos(m_theta)
return R
def forward(self, x, return_attn_weights=False):
b,m,d = x.shape
q = self.w_q(x)
k = self.w_k(x)
v = self.w_v(x)
q_out = (torch.bmm(q.transpose(0,1), self.R[:m, ...])).transpose(0,1)
k_out = (torch.bmm(k.transpose(0,1), self.R[:m, ...])).transpose(0,1)
v_out = (torch.bmm(v.transpose(0,1), self.R[:m, ...])).transpose(0,1)
activations, attn_weights = self.multihead(
q_out,k_out,v_out,
attn_mask=nn.Transformer.generate_square_subsequent_mask(m),
is_causal=True
)
if return_attn_weights:
return activations, attn_weights
return activations
layer = RoPEAttention(config)
batch = torch.randn((config['batch_size'], config['context_window'], config['d_model']))
output, attn_weights = layer(batch, return_attn_weights=True)
layer = RoPEAttention_wMask(MASTER_CONFIG)
batch = torch.ones((MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'], MASTER_CONFIG['d_model']))
output, attn_weights = layer(batch, return_attn_weights=True)
plt.imshow(attn_weights[0].detach().numpy())
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x16c2c7b50>
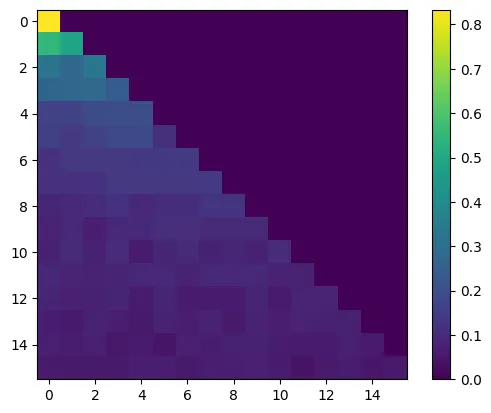
Alright, let’s run it and see what happens.
class RopeModel(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.embedding = nn.Embedding(config['vocab_size'], config['d_model'])
self.rms = RMSNorm((config['context_window'], config['d_model']))
self.rope_attention = RoPEAttention_wMask(config)
self.linear = nn.Sequential(
nn.Linear(config['d_model'], config['d_model']),
nn.ReLU(),
)
self.last_linear = nn.Linear(config['d_model'], config['vocab_size'])
print("model params:", sum([m.numel() for m in self.parameters()]))
def forward(self, idx, targets=None):
x = self.embedding(idx)
# one block of attention
x = self.rms(x) # rms pre-normalization
x = x + self.rope_attention(x)
x = self.rms(x) # rms pre-normalization
x = x + self.linear(x)
logits = self.last_linear(x)
if targets is not None:
loss = F.cross_entropy(logits.view(-1, self.config['vocab_size']), targets.view(-1))
return logits, loss
else:
return logits
model = RopeModel(MASTER_CONFIG)
xs, ys = get_batches(dataset, 'train', MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'])
logits, loss = model(xs, ys)
optimizer = torch.optim.Adam(model.parameters())
train(model, optimizer)
model params: 150465
validation loss: 2.1157416343688964
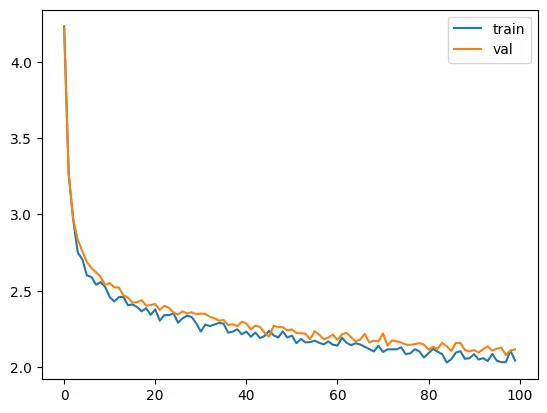
It looks like we can drive our loss down even lower. Let’s do that by updating master config.
MASTER_CONFIG.update({
"epochs": 5000,
"log_interval": 10,
})
train(model, optimizer)
validation loss: 1.9027801871299743
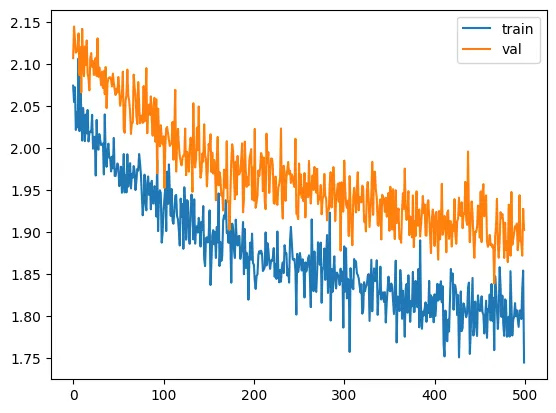
SwiGLU
As it says in the paper, “We replace the ReLU non-linearity by the SwiGLU activation function…we use a dimension of $frac{2}{3} 4d$ isntead of $4d$ as in PaLM.” SwiGLU is defined as:
SwiGLU(x)=Swishβ(xW+b)⊗(xV+c)
where $otimes$ is a component-wise product. The Swish function is defined as:
Swishβ(x)=xσ(βx)
where $beta$ is a learnable parameter.
class SwiGLU(nn.Module):
"""
Swish-Gated Linear Unit
https://arxiv.org/pdf/2002.05202v1.pdf
"""
def __init__(self, size):
super().__init__()
self.config = config
self.linear_gate = nn.Linear(size, size)
self.linear = nn.Linear(size, size)
self.beta = torch.randn(1, requires_grad=True)
self.beta = nn.Parameter(torch.ones(1))
self.register_parameter("beta", self.beta)
def forward(self, x):
swish_gate = self.linear_gate(x) * torch.sigmoid(self.beta * self.linear_gate(x))
out = swish_gate * self.linear(x)
return out
class RopeModel(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.embedding = nn.Embedding(config['vocab_size'], config['d_model'])
self.rms = RMSNorm((config['context_window'], config['d_model']))
self.rope_attention = RoPEAttention_wMask(config)
self.linear = nn.Sequential(
nn.Linear(config['d_model'], config['d_model']),
SwiGLU(config['d_model']),
)
self.last_linear = nn.Linear(config['d_model'], config['vocab_size'])
print("model params:", sum([m.numel() for m in self.parameters()]))
def forward(self, idx, targets=None):
x = self.embedding(idx)
# one block of attention
x = self.rms(x) # rms pre-normalization
x = x + self.rope_attention(x)
x = self.rms(x) # rms pre-normalization
x = x + self.linear(x)
logits = self.last_linear(x)
if targets is not None:
loss = F.cross_entropy(logits.view(-1, self.config['vocab_size']), targets.view(-1))
return logits, loss
else:
return logits
model = RopeModel(MASTER_CONFIG)
xs, ys = get_batches(dataset, 'train', MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'])
logits, loss = model(xs, ys)
optimizer = torch.optim.Adam(model.parameters())
train(model, optimizer)
model params: 183490
validation loss: 1.8666490197181702
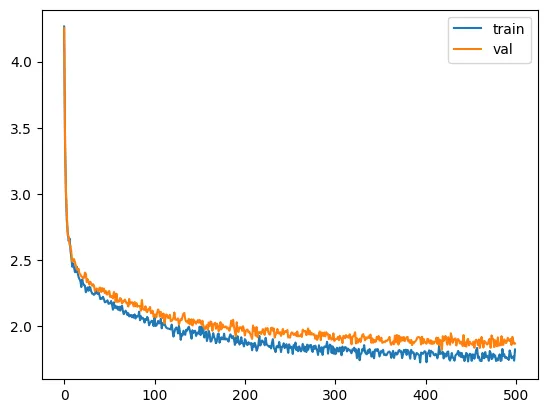
Now, let’s add multiple layers of RopeAttention by creating blocks.
# add RMSNorm and residual conncection
class LlamaBlock(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.rms = RMSNorm((config['context_window'], config['d_model']))
self.attention = RoPEAttention_wMask(config)
self.feedforward = nn.Sequential(
nn.Linear(config['d_model'], config['d_model']),
SwiGLU(config['d_model']),
)
def forward(self, x):
x = self.rms(x) # rms pre-normalization
x = x + self.attention(x)
x = self.rms(x) # rms pre-normalization
x = x + self.feedforward(x)
return x
block = LlamaBlock(MASTER_CONFIG)
block(torch.randn(MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'], MASTER_CONFIG['d_model']));
from collections import OrderedDict
MASTER_CONFIG.update({
'n_layers': 4,
})
class Llama(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.embeddings = nn.Embedding(config['vocab_size'], config['d_model'])
self.llama_blocks = nn.Sequential(
OrderedDict([(f"llama_{i}", LlamaBlock(config)) for i in range(config['n_layers'])])
)
self.ffn = nn.Sequential(
nn.Linear(config['d_model'], config['d_model']),
SwiGLU(config['d_model']),
nn.Linear(config['d_model'], config['vocab_size']),
)
print("model params:", sum([m.numel() for m in self.parameters()]))
def forward(self, idx, targets=None):
x = self.embeddings(idx)
x = self.llama_blocks(x)
logits = self.ffn(x)
if targets is None:
return logits
else:
loss = F.cross_entropy(logits.view(-1, self.config['vocab_size']), targets.view(-1))
return logits, loss
llama = Llama(MASTER_CONFIG)
optimizer = torch.optim.Adam(llama.parameters())
train(llama, optimizer, config=MASTER_CONFIG)
model params: 733382
validation loss: 1.616115140914917
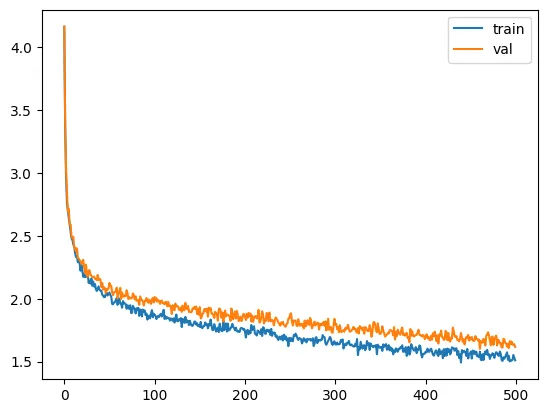
It looks like we can drive the loss down even more, and although we’re overfitting a little, I think we can still do better. Let’s train longer.
MASTER_CONFIG.update({
'epochs': 10000,
})
train(llama, optimizer, scheduler=None, config=MASTER_CONFIG)
validation loss: 0.9024032115936279
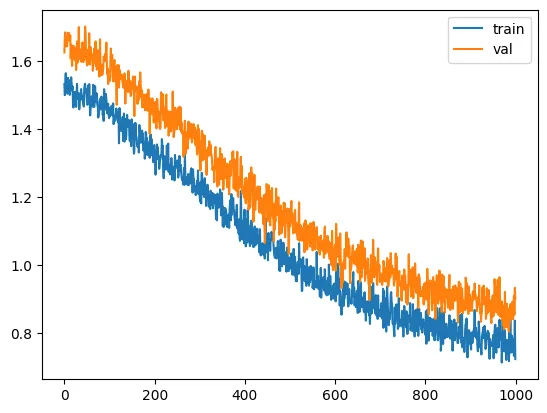
It seems we can go even lower, still without serious overfitting. Either there is a leak, or it’s actually doing well. The loss here is 1.08, which is equivalent to choosing between 2.9 tokens randomly.
train(llama, optimizer, config=MASTER_CONFIG)
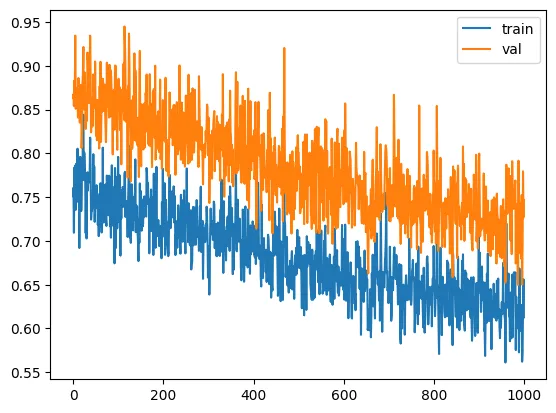
validation loss: 0.746810007095337
print(generate(llama, MASTER_CONFIG, 500)[0])
Evend her break of thou thire xoing dieble had side, did foesors exenatedH in siffied up,
No, none,
And you ling as thought depond.
MENENIUS:
Tell officien:
To pesiding be
Best wanty and to spiege,
To uncine shee patss again,
I will hen: then they
Moieth:
I my cast in letch:
For bereful, give toan I may
LINT OF AUMERLE:
Out, or me but thee here sir,
Why first with canse pring;
Now!
Gide me couuse
The haster:
And suilt harming,
Then as pereise with and go.
FROMNIUS:
I well? speak and wieke ac
At this point, we’ve hit the bottom with our training. Let’s test on the test set.
xs, ys = get_batches(dataset, 'test', MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'])
logits, loss = llama(xs, ys)
print(loss)
tensor(0.8304, grad_fn=<NllLossBackward0>)
Miscellaneous
Check for Gradient Flows
Let’s inspect the gradients, we want to see how they’re flowing. If there are too many gradients where the value is close to 0, that’s a problem.
# print the percentage that are near 0
def show_grads(model, tol=1e-2):
return sorted([(name, 100.0 * float(torch.sum(torch.abs(param) <= tol)) / float(param.nelement())) for name, param in model.named_parameters() if param.requires_grad], key=lambda t: t[1], reverse=True)
show_grads(llama)
[('llama_blocks.llama_0.attention.multihead.in_proj_bias', 36.71875),
('llama_blocks.llama_3.attention.multihead.in_proj_bias', 35.9375),
('llama_blocks.llama_1.attention.multihead.in_proj_bias', 33.59375),
('llama_blocks.llama_2.attention.multihead.in_proj_bias', 33.333333333333336),
('llama_blocks.llama_0.attention.multihead.in_proj_weight',
21.840413411458332),
('llama_blocks.llama_0.attention.w_q.weight', 14.892578125),
('llama_blocks.llama_0.attention.multihead.out_proj.weight', 13.4765625),
('llama_blocks.llama_0.attention.w_k.weight', 12.9638671875),
('llama_blocks.llama_0.attention.w_v.weight', 11.8896484375),
('llama_blocks.llama_1.attention.w_v.weight', 11.285400390625),
('llama_blocks.llama_3.attention.multihead.out_proj.weight', 11.12060546875),
('llama_blocks.llama_2.attention.w_v.weight', 10.68115234375),
('llama_blocks.llama_0.feedforward.0.weight', 10.4248046875),
('llama_blocks.llama_2.attention.multihead.out_proj.weight', 10.36376953125),
('llama_blocks.llama_1.attention.multihead.out_proj.weight', 10.2783203125),
('llama_blocks.llama_3.attention.multihead.out_proj.bias', 10.15625),
('llama_blocks.llama_3.attention.w_v.weight', 9.991455078125),
('llama_blocks.llama_0.feedforward.1.linear.weight', 9.9609375),
('llama_blocks.llama_1.attention.multihead.in_proj_weight',
9.908040364583334),
('llama_blocks.llama_2.attention.multihead.in_proj_weight', 9.75341796875),
('llama_blocks.llama_0.feedforward.1.linear_gate.weight', 9.66796875),
('llama_blocks.llama_1.attention.multihead.out_proj.bias', 9.375),
('llama_blocks.llama_3.attention.multihead.in_proj_weight', 9.16748046875),
('llama_blocks.llama_1.feedforward.0.weight', 8.77685546875),
('llama_blocks.llama_0.feedforward.1.linear_gate.bias', 8.59375),
('llama_blocks.llama_2.feedforward.1.linear.bias', 8.59375),
('llama_blocks.llama_2.feedforward.0.weight', 8.4228515625),
('llama_blocks.llama_1.feedforward.1.linear.weight', 7.720947265625),
('llama_blocks.llama_1.feedforward.1.linear_gate.weight', 7.501220703125),
('llama_blocks.llama_3.feedforward.0.weight', 7.440185546875),
('llama_blocks.llama_2.feedforward.1.linear.weight', 7.31201171875),
('llama_blocks.llama_2.feedforward.1.linear_gate.weight', 7.196044921875),
('llama_blocks.llama_1.feedforward.1.linear_gate.bias', 7.03125),
('llama_blocks.llama_2.attention.multihead.out_proj.bias', 7.03125),
('llama_blocks.llama_2.feedforward.1.linear_gate.bias', 7.03125),
('llama_blocks.llama_2.attention.w_k.weight', 6.94580078125),
('llama_blocks.llama_3.feedforward.1.linear.weight', 6.927490234375),
('llama_blocks.llama_1.attention.w_k.weight', 6.82373046875),
('llama_blocks.llama_2.attention.w_q.weight', 6.82373046875),
('llama_blocks.llama_3.attention.w_k.weight', 6.585693359375),
('llama_blocks.llama_3.feedforward.1.linear_gate.weight', 6.494140625),
('llama_blocks.llama_1.attention.w_q.weight', 6.396484375),
('llama_blocks.llama_1.feedforward.1.linear.bias', 6.25),
('llama_blocks.llama_3.feedforward.1.linear.bias', 6.25),
('llama_blocks.llama_3.attention.w_q.weight', 6.2255859375),
('ffn.0.weight', 5.633544921875),
('llama_blocks.llama_0.feedforward.1.linear.bias', 5.46875),
('ffn.1.linear_gate.bias', 5.46875),
('ffn.1.linear_gate.weight', 5.2978515625),
('ffn.1.linear.weight', 5.26123046875),
('ffn.2.weight', 4.447115384615385),
('ffn.1.linear.bias', 3.90625),
('llama_blocks.llama_0.feedforward.0.bias', 3.125),
('ffn.2.bias', 3.076923076923077),
('llama_blocks.llama_3.feedforward.0.bias', 2.34375),
('ffn.0.bias', 2.34375),
('llama_blocks.llama_0.attention.multihead.out_proj.bias', 1.5625),
('llama_blocks.llama_2.feedforward.0.bias', 1.5625),
('llama_blocks.llama_3.feedforward.1.linear_gate.bias', 1.5625),
('llama_blocks.llama_1.feedforward.0.bias', 0.78125),
('embeddings.weight', 0.7572115384615384),
('llama_blocks.llama_0.rms.scale', 0.146484375),
('llama_blocks.llama_0.feedforward.1.beta', 0.0),
('llama_blocks.llama_1.rms.scale', 0.0),
('llama_blocks.llama_1.feedforward.1.beta', 0.0),
('llama_blocks.llama_2.rms.scale', 0.0),
('llama_blocks.llama_2.feedforward.1.beta', 0.0),
('llama_blocks.llama_3.rms.scale', 0.0),
('llama_blocks.llama_3.feedforward.1.beta', 0.0),
('ffn.1.beta', 0.0)]
Here, for all of our parameter gradients, the vast majority are non-zero, which is great. If we start to see this number peak higher, then our gradients would not be flowing.
Experiment with hyperparams, aka “change the oven settings”
In the original Llama paper, the authors use Cosine Annealing learning schedule. We didn’t do that here, because I experimented and saw that it was worse.
MASTER_CONFIG.update({
"epochs": 1000
})
llama_with_cosine = Llama(MASTER_CONFIG)
llama_optimizer = torch.optim.Adam(
llama.parameters(),
betas=(.9, .95),
weight_decay=.1,
eps=1e-9,
lr=1e-3
)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(llama_optimizer, 300, eta_min=1e-5)
train(llama_with_cosine, llama_optimizer, scheduler=scheduler)
model params: 733382
/Users/bkitano/Desktop/projects/llama/.llama/lib/python3.11/site-packages/torch/optim/lr_scheduler.py:814: UserWarning: To get the last learning rate computed by the scheduler, please use `get_last_lr()`.
warnings.warn("To get the last learning rate computed by the scheduler, "
lr: [0.0009999457184159408]
lr: [0.0009961510274583004]
lr: [0.0009869757772816292]
lr: [0.0009725204933511963]
lr: [0.0009529435502760634]
lr: [0.0009284594366176498]
lr: [0.0008993364049014041]
lr: [7.128036241775617e-05]
lr: [4.872936226262451e-05]
lr: [3.117756953567661e-05]
lr: [1.8816750064937722e-05]
validation loss: 4.179551410675049
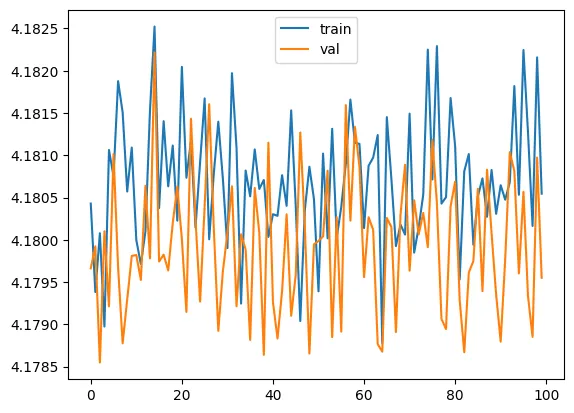
show_grads(llama_with_cosine, 1e-5)
[('llama_blocks.llama_0.attention.multihead.in_proj_bias', 100.0),
('llama_blocks.llama_0.attention.multihead.out_proj.bias', 100.0),
('llama_blocks.llama_1.attention.multihead.in_proj_bias', 100.0),
('llama_blocks.llama_1.attention.multihead.out_proj.bias', 100.0),
('llama_blocks.llama_2.attention.multihead.in_proj_bias', 100.0),
('llama_blocks.llama_2.attention.multihead.out_proj.bias', 100.0),
('llama_blocks.llama_3.attention.multihead.in_proj_bias', 100.0),
('llama_blocks.llama_3.attention.multihead.out_proj.bias', 100.0),
('llama_blocks.llama_1.feedforward.1.linear.bias', 0.78125),
('llama_blocks.llama_2.feedforward.1.linear_gate.weight', 0.030517578125),
('llama_blocks.llama_3.attention.w_q.weight', 0.030517578125),
('llama_blocks.llama_0.attention.multihead.out_proj.weight', 0.0244140625),
('llama_blocks.llama_0.feedforward.1.linear_gate.weight', 0.0244140625),
('llama_blocks.llama_0.feedforward.1.linear.weight', 0.0244140625),
('llama_blocks.llama_1.attention.w_v.weight', 0.0244140625),
('llama_blocks.llama_1.feedforward.1.linear.weight', 0.0244140625),
('llama_blocks.llama_2.attention.w_q.weight', 0.0244140625),
('llama_blocks.llama_3.attention.w_v.weight', 0.0244140625),
('llama_blocks.llama_3.attention.multihead.out_proj.weight', 0.0244140625),
('ffn.2.weight', 0.02403846153846154),
('llama_blocks.llama_0.attention.w_v.weight', 0.018310546875),
('llama_blocks.llama_0.feedforward.0.weight', 0.018310546875),
('llama_blocks.llama_1.feedforward.0.weight', 0.018310546875),
('llama_blocks.llama_3.attention.w_k.weight', 0.018310546875),
('llama_blocks.llama_3.feedforward.0.weight', 0.018310546875),
('llama_blocks.llama_0.attention.multihead.in_proj_weight',
0.016276041666666668),
('llama_blocks.llama_1.attention.multihead.out_proj.weight', 0.01220703125),
('llama_blocks.llama_1.feedforward.1.linear_gate.weight', 0.01220703125),
('llama_blocks.llama_3.feedforward.1.linear_gate.weight', 0.01220703125),
('llama_blocks.llama_3.feedforward.1.linear.weight', 0.01220703125),
('llama_blocks.llama_0.attention.w_q.weight', 0.006103515625),
('llama_blocks.llama_0.attention.w_k.weight', 0.006103515625),
('llama_blocks.llama_1.attention.w_q.weight', 0.006103515625),
('llama_blocks.llama_1.attention.multihead.in_proj_weight', 0.006103515625),
('llama_blocks.llama_2.attention.multihead.in_proj_weight', 0.006103515625),
('llama_blocks.llama_2.attention.multihead.out_proj.weight', 0.006103515625),
('llama_blocks.llama_2.feedforward.1.linear.weight', 0.006103515625),
('llama_blocks.llama_3.attention.multihead.in_proj_weight',
0.004069010416666667),
('embeddings.weight', 0.0),
('llama_blocks.llama_0.rms.scale', 0.0),
('llama_blocks.llama_0.feedforward.0.bias', 0.0),
('llama_blocks.llama_0.feedforward.1.beta', 0.0),
('llama_blocks.llama_0.feedforward.1.linear_gate.bias', 0.0),
('llama_blocks.llama_0.feedforward.1.linear.bias', 0.0),
('llama_blocks.llama_1.rms.scale', 0.0),
('llama_blocks.llama_1.attention.w_k.weight', 0.0),
('llama_blocks.llama_1.feedforward.0.bias', 0.0),
('llama_blocks.llama_1.feedforward.1.beta', 0.0),
('llama_blocks.llama_1.feedforward.1.linear_gate.bias', 0.0),
('llama_blocks.llama_2.rms.scale', 0.0),
('llama_blocks.llama_2.attention.w_k.weight', 0.0),
('llama_blocks.llama_2.attention.w_v.weight', 0.0),
('llama_blocks.llama_2.feedforward.0.weight', 0.0),
('llama_blocks.llama_2.feedforward.0.bias', 0.0),
('llama_blocks.llama_2.feedforward.1.beta', 0.0),
('llama_blocks.llama_2.feedforward.1.linear_gate.bias', 0.0),
('llama_blocks.llama_2.feedforward.1.linear.bias', 0.0),
('llama_blocks.llama_3.rms.scale', 0.0),
('llama_blocks.llama_3.feedforward.0.bias', 0.0),
('llama_blocks.llama_3.feedforward.1.beta', 0.0),
('llama_blocks.llama_3.feedforward.1.linear_gate.bias', 0.0),
('llama_blocks.llama_3.feedforward.1.linear.bias', 0.0),
('ffn.0.weight', 0.0),
('ffn.0.bias', 0.0),
('ffn.1.beta', 0.0),
('ffn.1.linear_gate.weight', 0.0),
('ffn.1.linear_gate.bias', 0.0),
('ffn.1.linear.weight', 0.0),
('ffn.1.linear.bias', 0.0),
('ffn.2.bias', 0.0)]
Even at an extremely low tolerance, the attention biases are not getting any signal. I’m not sure why the learning schedule from the paper doesn’t work, but the lesson here is simple: start simple.