The following article describes how Large Language Models (LLMs) fit in the open-source world, covering LLaMA2 and why it isn’t as open-source as we think.
https://www.alessiofanelli.com/blog/llama2-isnt-open-source
Almost a decade ago I started an open source company, and I’ve since been involved in the OSS community as a founder, contributor, speaker, and investor. The internet wouldn’t be what it is today if it wasn’t for the amazing open source projects that power most of the digital infrastructure of our world, so it’s a topic that has always been close to my heart.
When LLaMA2 came out, many of the folks I respect in the community were upset about misusing the term “open source” when referring to the model.
Yann
While it’s mostly open, there are caveats such as you can’t use the model commercially if you had more than 700M MAUs as of the release date, and you also cannot use the model output to train another large language model. These types of restrictions don’t play well with the open source ethos. But while I agree that LLaMA2 cannot be called open source in the traditional meaning of the word, I also think that it doesn’t matter. The term “open source” needs to evolve (once again) in the world of AI models.
From Free to Open
I wrote a long history of the free software and open source movement here, so I won’t bore you with the details again. What you need to know is that since the 1976 “Open Letter to Hobbyists”, there’s always been tension between the commercial interests of software companies and the curiosity of hackers who wanted to circumvent its restriction. The “free software” movement started in the 70s in the MIT AI lab with Richard Stallman and eventually the GNU project in 1983. The GPL “copyleft” license was created, and projects like Red Hat, MySQL, Git, and Ubuntu adopted it.
The term “open source” came to be in 1998 thanks to MIT’s Christine Peterson; at the “Freeware Summit”, the term “free software” was officially deprecated in favor of “open source software”. As time went by, the “free” and “open source” software communities diverged as they had different ideas of what free and open meant. Free software, as specified by the Free Software Foundation, is only a subset of open source software and uses very permissive licenses such as GPL and Apache.
In the last decade, there was another bifurcation, this time created by the tension between commercial open source companies and the cloud hyperscalers. Elastic and MongoDB transitioned their open source projects to the “Server-Side Public License” (SSPL) which allows developers to use the product commercially, as long as what they are offering isn’t a hosted version of the product. The goal was to block AWS from re-hosting their products as cloud services and profiting from them. The SSPL also infringes on the OSS ideals and is not recognized by the OSI as an open source license. Yet, the majority of developers still say that MongoDB is open source. More and more the term “open source” is losing its freedom connotations and turning almost synonymous with “source available” in developers’ minds.
From Source to Weights
With the rise of open models like Dolly, MPT, LLaMA, etc., we are seeing a similar bifurcation in the community. For most AI engineers, “open source” today means “downloadable weights”, nothing more. Heather Meeker has proposed a definition for “open weights”, but there’s still no community consensus. The question is whether or not open weights are enough for a model to be called open source; a software analogy would be a project releasing its binaries without the source code to re-build it from scratch.
For a model to be truly open source and retrainable from scratch, the creators would need to share all their training code, pre-training dataset, fine-tuning preferences, RLHF examples, etc. The problem is the cost of these training runs: even if someone were to release everything, it’s cost-prohibitive to train models from scratch for most developers and companies, so having access to the final weights is preferred anyway.
Open Models
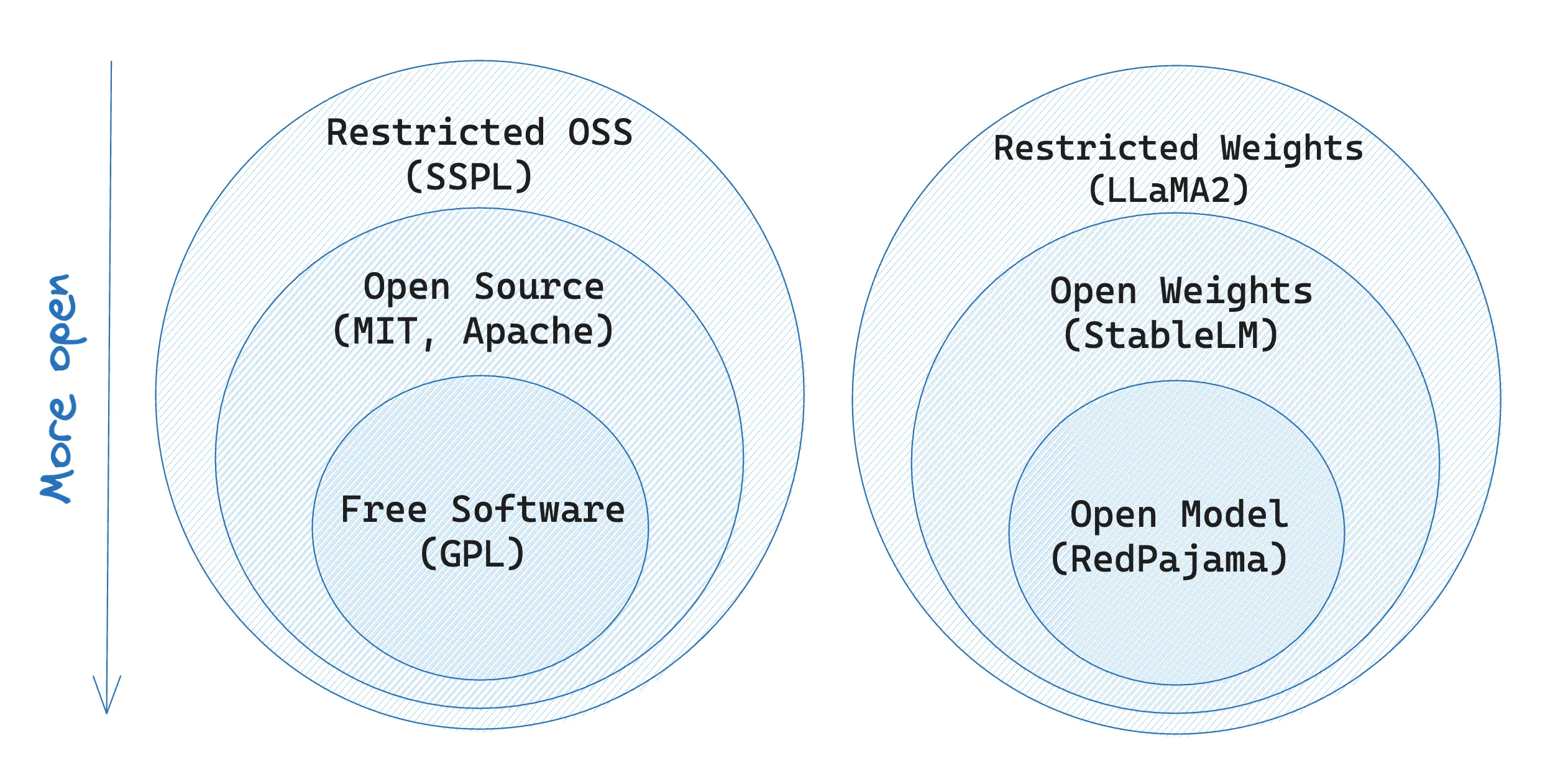
In the LLMs space, the term “open source” is used interchangeably to define a wide range of openness levels:
- Open models: these are models like RedPajama and MPT-7B, they have open weights available for commercial use (under Apache 2.0 license), but can also be re-trained from scratch since the dataset is open source. You can find a guide on how to train your own RedPajama model here.
- Open weights: StableLM is an open model trained by StabilityAI. While the weights are available and are licensed under Apache 2.0, the dataset used to train isn’t available to the public. From their README: “StableLM-Base-Alpha is pre-trained on a new experimental dataset built atop The Pile and is threes times larger at approximately 1.5T tokens.”
- Restricted weights: this is LLaMA2. The pre-training dataset is also unavailable, and while the weights are supposed to be open for commercial use, they have specific limitations that we mentioned above.
- Contaminated weights: models like Dolly 1.0 and LLaMA1 are part of this category. The weights are released openly, but the dataset used to train them doesn’t allow for commercial use, making it technically open but practically unusable.
For the foreseeable future, open source and open weights will be used interchangeably, and I think that’s okay. The important thing is that more and more of this work is done as openly as possible. It’s okay to be disappointed with the LLaMA2 license, but Meta just packaged ~$2M worth of FLOPS into a Github repo, and I think that will be a net positive for the progress of this space.