The following articles explains the concept of the outbox pattern and streaming database in the context of a micro-service architecture.
https://dev.to/bobur/reliable-microservices-data-exchange-with-streaming-database-pdo
Nowadays we usually build multiple services for a single product to work and client apps need to consume functionality from more than one service. Microservices architecture has become a popular approach for building scalable and resilient applications. In a microservices-based system, multiple loosely coupled services work together to deliver the desired functionality. One of the key challenges in such systems is exchanging data between microservices in a reliable and efficient manner. One pattern that can help address this challenge is the Outbox pattern.
In this article, we will explore how to implement the outbox pattern with a streaming database which can provide a reliable solution for microservices or multiple services data exchange.
The need for reliable microservices data exchange
In a microservices architecture, each microservice has business logic, is responsible for its own data, has its own local data store, and performs its own operations on that data (Data per service pattern). However, there are scenarios where microservices need to share data with each other or notify other services about any specific data change in real-time in order to maintain consistency and provide a cohesive experience to end users. For example, consider in a ride-hailing service, there may be multiple microservices responsible for different functionalities, such as user management, ride booking, driver management, and payment processing. When a user requests a ride, it triggers a series of events that need to be propagated to various microservices for processing and updating their data.
Ride-hailing services are where a customer orders the ride from a ride-hailing platform. The best-known such services are Uber, Lyft, and Bolt.
Traditional synchronous communication between microservices can lead to tight coupling and potential performance and reliability issues. A sending service needs to know the location, interface, and contract of other microservices, which can result in a complex web of dependencies. This can make it challenging to evolve, test, and deploy microservices independently, as any change in one microservice may require changes in multiple dependent microservices. Sometimes these target services might temporarily not be available and can introduce performance overhead due to the need for waiting and blocking until a response is received.
Asynchronous and decoupled data exchange
On the other hand, the Outbox pattern promotes asynchronous and decoupled data exchange between microservices. When an event or change occurs in one microservice, it writes the event or changes to its outbox, which acts as a buffer. The outbox can be implemented as a separate database table that the service owns.
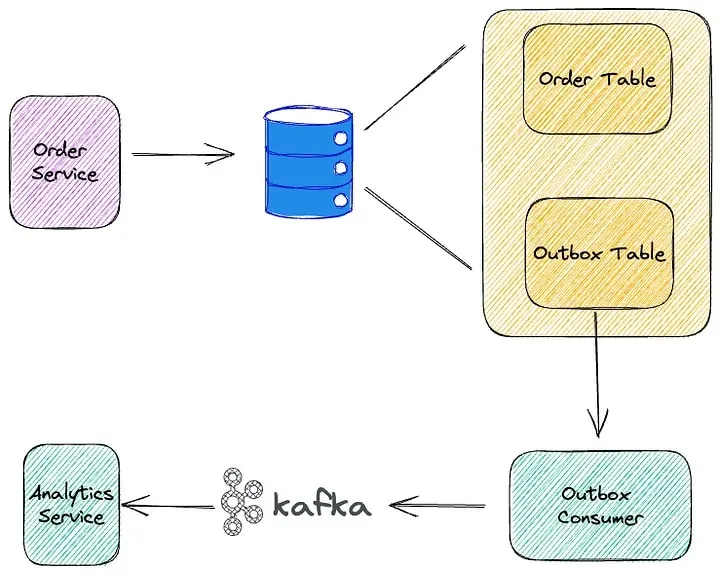
Outbox pattern microservice
The microservice’s outbox is then processed by an Outbox Processor (by a separate component or service such as a streaming database RisingWave which is explained in the below section), which reads the events or changes from the outbox and sends them to other microservices or data stores asynchronously. This allows microservices to continue processing requests without waiting for the data exchange to complete, resulting in improved performance and scalability.
Microservice B, which needs to be updated with the changes from Microservice A, receives the events or changes from the outbox processor and applies them to its own state or data store. This ensures that Microservice B’s data remains consistent with the changes made in Microservice A.
Now let’s see how the Outbox pattern can be implemented using the streaming database with an example of RisingWave. There are other streaming database options in the market, this post helps you understand what is streaming database is, when, and why to use it, and discusses some key factors that you should consider when choosing the right streaming database for your business.
RisingWave is a streaming database that helps in building real-time event-driven services. It can read directly database change events from traditional databases binlogs or Kafka topics and build a materialized view by joining multiple events together. RisingWave will keep the view up to date as new events come and allow you to query using SQL to have access to the latest changes made to the data.
Outbox pattern with a streaming database
The streaming database can act as a real-time streaming platform (outbox processor). It listens to any write/update operations in the specified database table using its built-in Change Data Capture (CDC) connector, captures changes, and propagates those changes to other microservices in real-time or near real-time with the help of Kafka topics (See how to sink data from RisingWave to a Kafka broker).
In this article, the author Gunnar Morling explains another implementation of the outbox pattern based on CDC and the Debezium connector.
Some key advantages when using the streaming database are that you do not need to use both Debezium and Kafka connect to achieve the same, also it has its own storage you never lose streaming data and you can create materialized views optimized for querying microservices which explained in my other blog post.
Plus, it gives us the ability to analyze the data by delivering them to BI and data analytics platforms for making better business decisions based on your application usage. For example, a trip history view is an important feature in a ride-hailing service to provide passengers and drivers with access to their trip history. Instead of querying the individual trip records and calculating various statistics such as total trips, earnings, ratings, etc., a materialized view can be used to store the precomputed trip history information for each user in the streaming database.
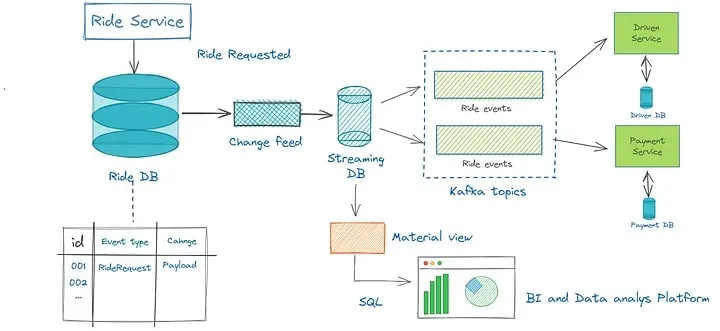
Reliable Microservices Data Exchange
With the Outbox pattern and streaming database, here’s how the data exchange could work for our example ride-hailing service:
- Ride Service (Microservice A): When a user requests a ride, the Ride Service creates the ride details and writes an event, such as “RideRequested”, to its outbox table in its own database let’s say MySQL.
- By default, the streaming database captures the “RideRequested” event from the Ride Service’s outbox table using its connector for MySQL CDC. It processes the event and sends it to other microservices that need to be updated, such as Driver Service (Microservice B), Payment Service (Microservice C), and Notification Service (Microservice D), using a message broker like Apache Kafka.
- Driver Service (Microservice B): The Driver Service receives the “RideRequested” event from the Outbox Processor and finds an available driver for the ride based on the ride details. It then writes an event, such as “DriverAssigned”, to its own outbox.
- Payment Service (Microservice C): The Payment Service also receives the “RideRequested” event from another Kafka topic and calculates the fare for the ride based on the ride details. It then writes an event, such as “FareCalculated”, to its own outbox.
We can create multiple Kafka topics to give options to consumer services to subscribe to only specific event types.
Conclusion
As we understood, synchronous communication between microservices can introduce tight coupling, performance overhead, lack of fault tolerance, limited scalability, versioning challenges, and reduced flexibility and agility. By leveraging real-time streaming platforms such as RisingWave and decoupling the data exchange process from the main transactional flow by applying an outbox pattern, you can achieve high performance, reliability, and consistency in your microservices architecture.
#reads #bobur umurzokov #microservices #software architecture