The following is an overview on the new cloud service available in AWS - S3 Express - and how big data companies can profit from it.
https://www.warpstream.com/blog/s3-express-is-all-you-need
The new “AWS S3 Express One Zone” low latency storage class is making waves in the data infrastructure community. A lot of people are starting to ask the obvious question: How much will it cost in practice, and what does this mean for the future of data infrastructure?
The first thing to know is that the new S3 Express storage class costs 8x more than S3 Standard per GiB stored which makes it unsuitable as the “primary” store for big data systems like Kafka and traditional data lakes.
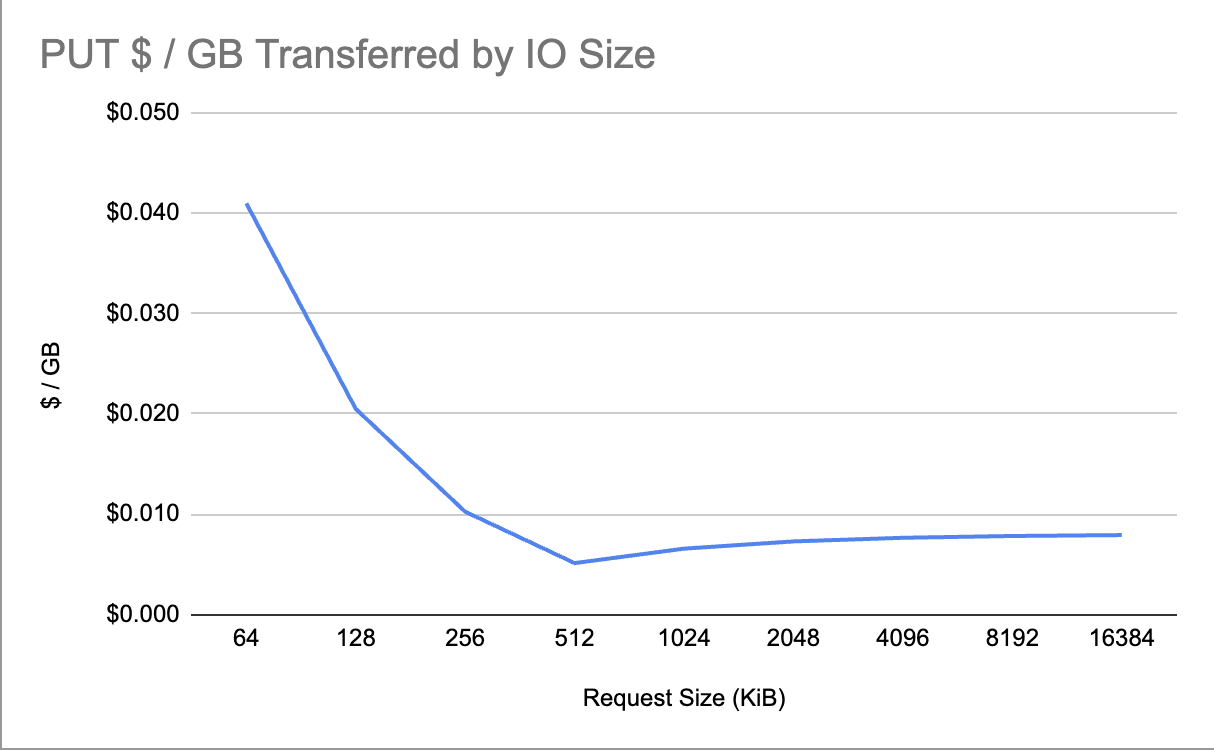
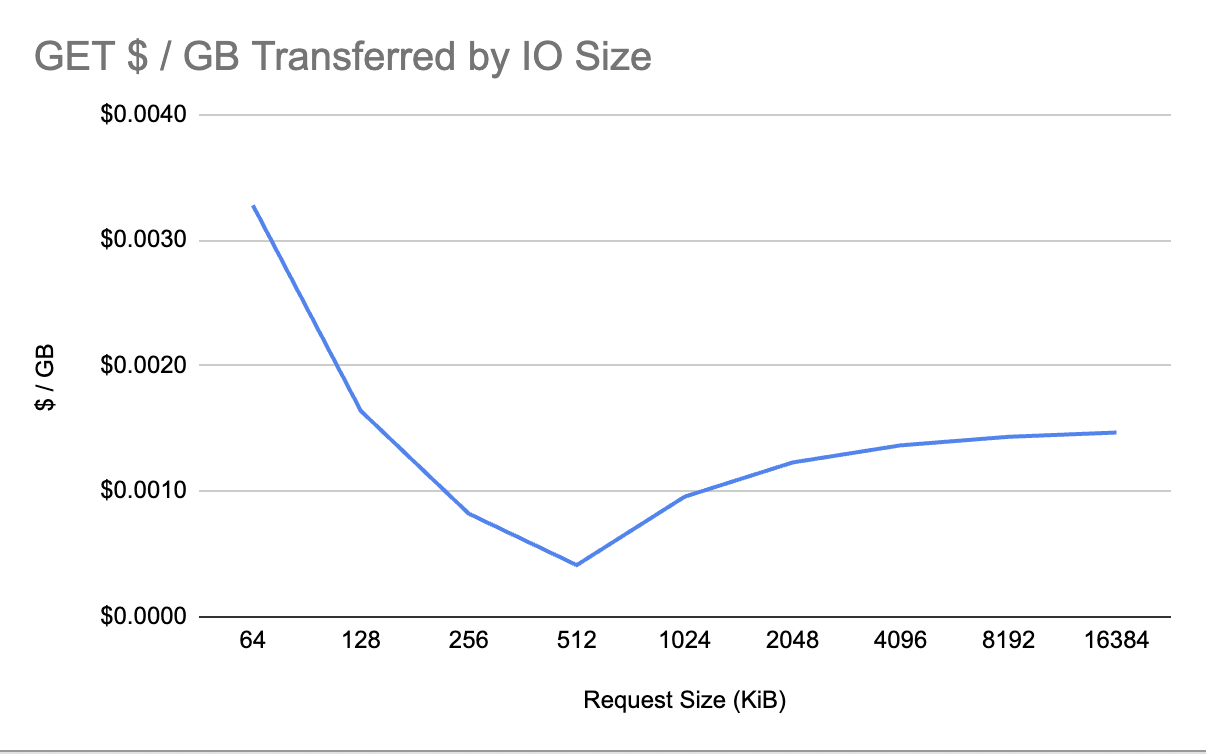
However, individual API operations are 50% cheaper. 50% cheaper is great, but it’s not 10-20x cheaper. That means any workloads that were previously impractical due to S3 API operation costs are still impractical with the new Express storage class. Unlike S3 Standard, however, the new Express class also charges per GiB for every API operation (writes + reads) beyond 512 KiB. Another way to think about this is that every API operation comes with 512 KiB of bandwidth “free” and you pay for every byte beyond that.
We did some simple cost modeling, and this is what the cost profile looks like for PUT requests:
Here’s what it looks like for GET requests:
However, remember that the new Express storage class is single zone. That means most modern data systems will have to manually replicate their data to two different availability zones if they want to survive the failure of a single AZ with no data loss or unavailability. So let’s double those numbers.
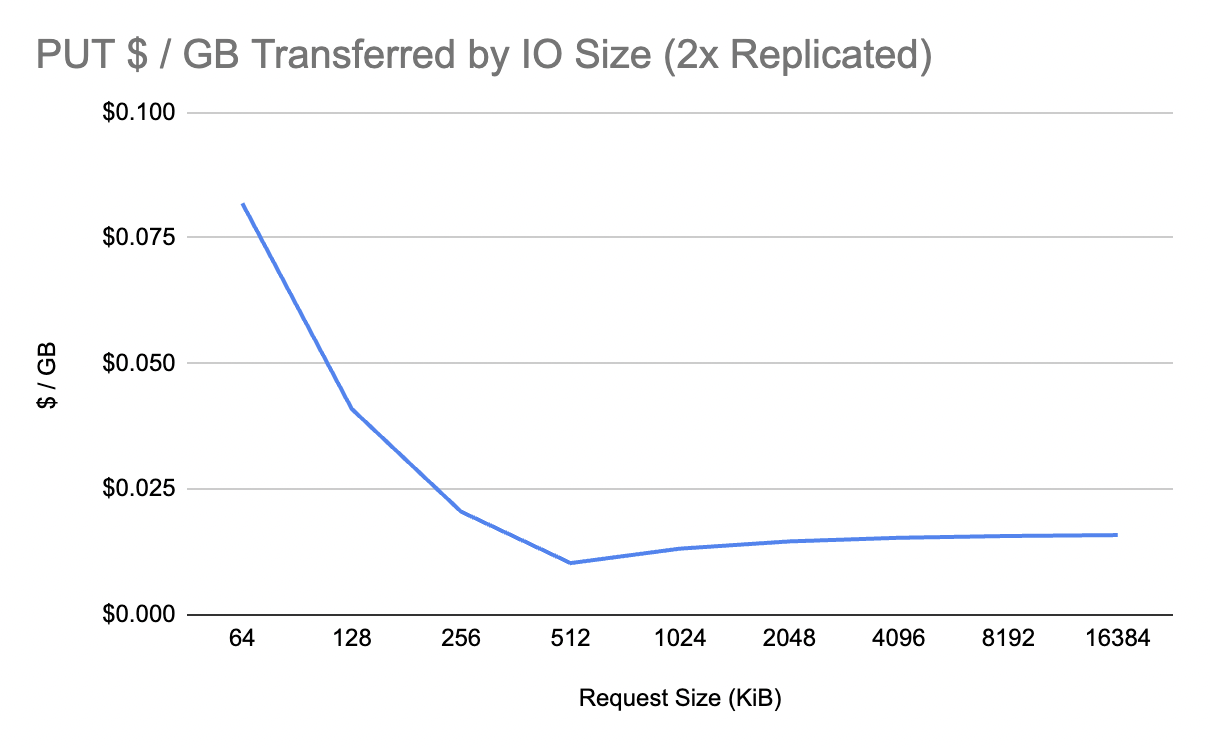
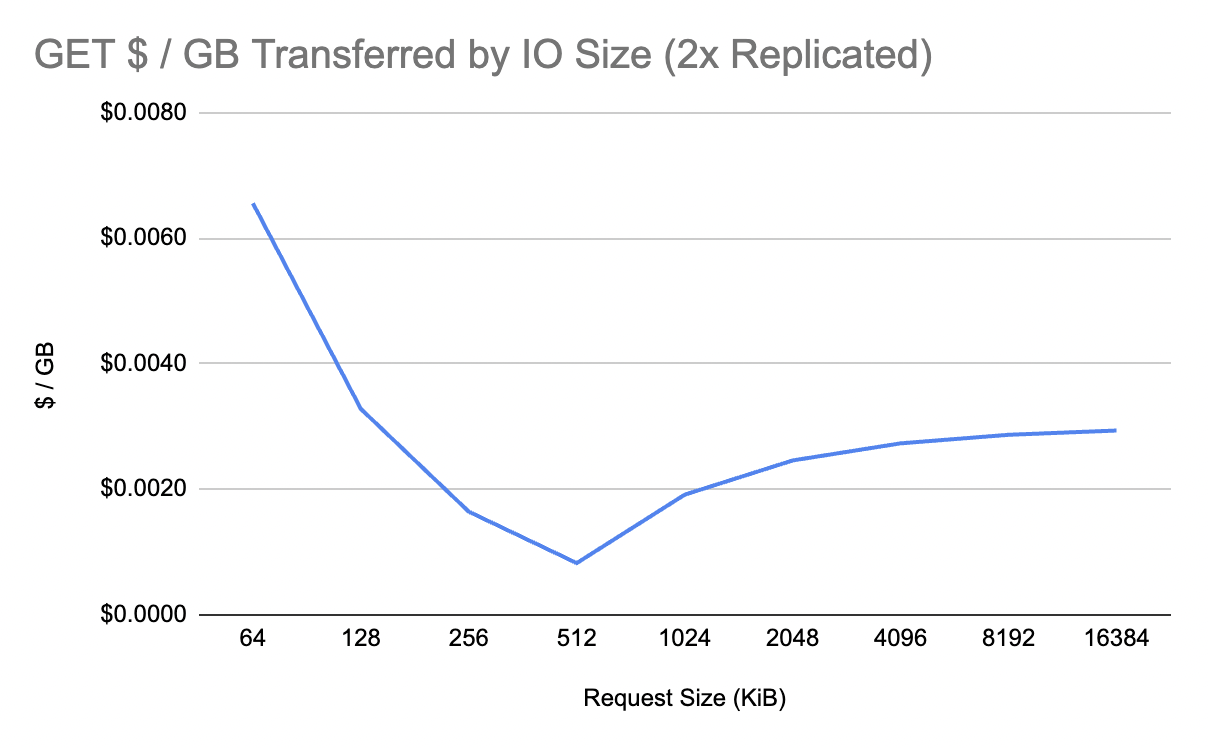
If you squint, the $0.016/GiB it costs to write data twice to two different S3 Express buckets in two different availability zones is suspiciously close to the cost of manually replicating a GiB of data between two availability zones at the application layer ($0.02/GiB). In other words, for high volume use cases, the new S3 Express storage class does not expose many new opportunities for dramatic improvements in cost or performance compared to traditional doubly or triply replicated storage systems.
However, the new storage class does open up an exciting new opportunity for all modern data infrastructure: the ability to tune an individual workload for low latency and higher cost or higher latency and lower cost with the exact same architecture and code. This will be a huge leap forward for modern data infrastructure as there is no longer any reason to design any large-scale modern data system around the availability of local disks, or block storage (like EBS).
All modern data systems, even those that need to serve low latency operational workloads, can now be built completely around object storage with data tiering only performed between object storage tiers. In the worst case scenario, it will still be cheaper, more durable, and significantly less error prone than manually replicating data at the application layer. In the best case scenario, you’ll be able to cut costs by an order of magnitude for high volume use cases without touching a line of code.
Of course the AWS S3 Express storage costs are still 8x higher than S3 standard, but that’s a non issue for any modern data storage system. Data can be trivially landed into low latency S3 Express buckets, and then compacted out to S3 Standard buckets asynchronously. Most modern data systems already have a form of compaction anyways, so this “storage tiering” is effectively free.