The following article covers what it needs to succeed in a serverless architecture using Lambdas (AWS). It also does the math related to what costs more: going pure serverless or renting server instances.
Serverless computing, with Lambda functions at the heart of it, has irrevocably changed the way we build and scale applications, more than anything, by adding another question to the list of questions in the beginning of every project:
“Should we do this serverless”
And although sometimes the answer is as simple as “None of our other systems are serverless, let’s not start mixing them”, a lot of other times it’s more complicated than that. Partially because:
“Serverless architecture promises flexibility, infinite scalability, fast setups, cost efficiency, and abstracting infrastructure allowing us to focus on the code. But does it deliver?”
With a technology that makes these promises it’s hard to mute that voice inside us asking questions like:
“what if it’s easier to maintain? Maybe it’s at least easier to spin up? Could it make us go faster? Would it be cheaper? What if we can scale more easily?”
Therefore, sooner or later we all will be intrigued enough to search it more, or implement it in a PoC just to see if it makes sense to go forward. And that’s where it gets tricky!
At Adadot we ran over 200 million Lambdas in the last year. In this year-long journey to harness the power of Lambda functions, we saw both good and sides of them that we didn’t really expect.
Our Setup
Context: At Adadot we building the only dev-first analytics platform, which at the end of the day means A LOT of data. So capturing and processing big volumes of data is our focus.
When we started, we were a small team of a couple of software engineers, and we didn’t know how the system requirements would need to scale over the next year(s). We had very little production experience of serverless architectures, but each one of us a decade with “traditional” architectures. We thought we at least knew the below about serverless:
- It would scale “infinitely”, as long as we have enough money to throw on it, so it could save us in a scenario of unexpected traffic growth.
- We won’t have to pay almost anything as long as our traffic is very low
- Lambdas specifically have high warmup times, and we dont wanna have to manage warm up strategies, or use provisioned capacity (I’ll explain this in-depth in another article)
So since we had no clue how our traffic would be over the next years, we took early on a decision on our architecture’s principles:
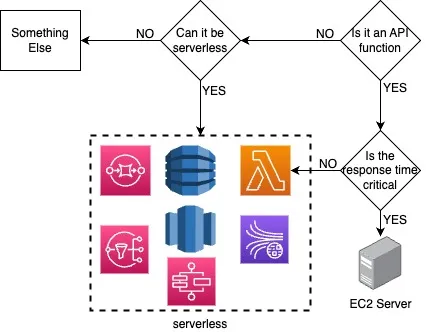
- Any API that is customer-facing, needs fast response and doesn’t do heavy operations will be handled by an always-on server.
- Any other function would be run in lambdas.
- Anything else that can be serverless (databases, queues, streams etc) will be serverless.
- Cost evaluation is to be performed periodically as traffic gets more predictable to re-evaluate.
Fast forward 2 years, and especially due to our requirements on what to deliver to the end-users, we ended up with a serverless-heavy architecture, which includes only 1 “monolithic” API server and some always-on databases, but also about 200 lambdas, 100 step functions, 100 kinesis streams, 100 SQS, DynamoDB (including streams), Redshift & Neptune clusters, API Gateways and a whole bunch on AWS networking components.
And all that is how we got to us running over 200 million lambdas in the last year alone. However, as you may have deduced from the above these were not serving customer-facing APIs, but rather various tasks we had to do on the backend, based on various different triggers and events in order to have all of your data ready, in the right format, and with the required analyses done so our customers could have access to them.
So without further ado, let’s move on to the more interesting part of what we learned out of this year.
Ease & Speed
So are Lambdas easier to spin up? For us that has been a constant and resounding “yes” throughout our whole journey. We found that Lambdas need significantly less configuration and setup in order to spin up and start working, and less initial thinking over instance sizing configurations. We are using the serverless framework for our Lambdas, so in order to have a Lambda function up and running it’s as simple as creating the serverless.yml file and running `serverless deploy`. We mainly use JS (with TypeScript) and Python, so something like the below is enough to have a function up and running even including bundling, IAM permissions, environmental variables, x-ray tracing, custom layers and really everything needed for each one. So really once you’ve written the function in 5 minutes you are ready to go.
serverless.yml for TypeScript and Python
serverless.yml for TypeScript and Python
serverless.yml for TypeScript and Python
serverless.yml for TypeScript and Python
That being said, we use Terraform to manage the rest of our infrastructure, but we found that managing Lambda functions using Terraform was of significantly bigger complexity. That means however, that we have 2 different ways to manage our infrastructure, and they don’t play that well between them, meaning that they don’t really communicate resource information, so unfortunately that means, that there are cases that the id of a resource needs to be hardcoded or put as a wildcard to be used by the other.
Infinite (or not) Scaling
Usually serverless architectures are presented as being “infinitely horizontally scaling”, which is, at most times, too good to be true. And I’m obviously not talking about the practical impossibility of anything reaching infinity, but a much much more tangible limit. In the case of Lambdas that limit is the maximum amount of unreserved – or reserved – concurrency. These two types of concurrencies can be summarized as below:
- Unreserved concurrency is the maximum amount of concurrent Lambda executions for an AWS account, once you reach that amount you are getting throttled by AWS (ouch!)
- Reserved concurrency is an amount of the unreserved concurrency that you have reserved for a specific Lambda function. That amount can only be used by that function and is the maximum amount that that function can use.
So unreserved is the maximum amount for the account. For our region that limit is set to 1000. That might sound like a lot when you start, but you quickly realise it’s easy to reach once you have enough Lambdas and you scale up. We found ourselves hitting that limit a lot once our traffic and therefore our demands from our system started scaling.
For us the answer was to:
- implement an improved caching logic and not rerun heavy operations when they had already been calculated before and
- spread the calculation loads throughout the day, depending on the end-users timezone.
You can see the difference these made for us in the graph below (note that we had less than 700 unreserved concurrency because we had reserved the rest).

Daily concurrent lambda execution
Daily concurrent lambda execution
Function Resources
Upon setting up a Lambda function you have to set up the amount of memory for the container, and that will internally be reflected as a CPU specification for the Lambda function container. There is a limit of 10Gb. Although if we were to do everything with Lambda we would reach that limit easily, it generally hasn’t been an issue for us. Where the issue lies is that
“cost of lambda = memory * execution time”
Which means these settings have massively affected the cost of the Lambdas. All good up to here, however, it gets more complicated if the function load is not always constant, but depends on some external parameters (e.g. the volume of data for the user). You are then forced to put the Lambda memory on the highest setting even if it’s the 99th percentile of your Lambdas’ loads, and overpay 99% of the times. You can not just say “take as much as you need” (for obvious reasons). So
the classic old problem of “how big should our server be” is still there, you just don’t need to ask “how many of them” as long as they follow the other limits
Storage Limits
Unless you go for the hard path of using Fargates (which we had to do in cases), Lambdas have a size limit of 10GB container image (uncompressed including layers), and for all account’s Lambdas combined there is a limit of 75GB. That might sound like plenty, and it might indeed be, but it heavily depends on what language you use for your Lambda. If you use a language that has a sort of tree-shaking so you upload only what you really use (e.g. JS) then you are probably covered forever. On the other hand, for other languages (looking at you, Python), 10GB is hardly enough. Once you import Pandas you’re on the limit. You can forget Pandas and scipy at the same Lambda.
Time Limits
Initially we thought “it’s just like an on-demand server”. It spins up, does what you need and drops down again. Yes and no. It spins up and does what you want, but only up to 15 minutes, and drops again. If a task needs more than 15 minutes to finish you have to go a different way. Also, of course, if a function runs 99.9% of the time relatively fast, but the rest 0.01% it takes consistently more than 15 minutes, you need to find an alternative, or break it into smaller pieces. This is part of why we have about 200 Lambda functions, as we were not really happy with the logging retention of Fargate, we chose to stay mostly on Lambdas and kept breaking them into executable chunks. Also in our case a lot of the timeouts were expected and acceptable due to backoffs on the downstream resources, so our system is resilient to this. Still our execution duration graph shows how far is the average execution time to the maximum.
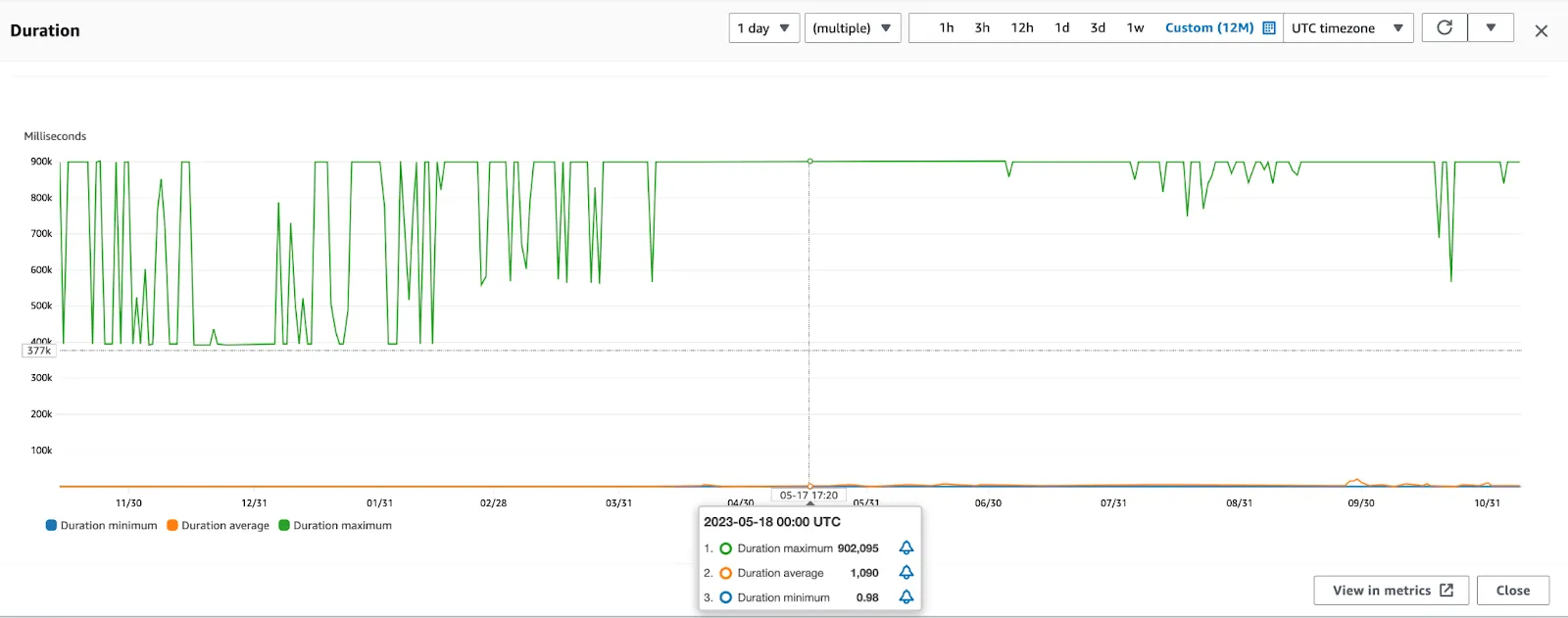
Max, min and average daily lambda execution durations
Max, min and average daily lambda execution durations
Monitor and Analyze
Proper monitoring and logging are essential for maintaining visibility into your serverless application. Especially when they are triggered not by customer-request, but by events. You really should not just fire and forget them, cause it’s really easy for nothing to work without anyone noticing unless you go above and beyond on your monitoring and alerting.
AWS provides tools like CloudWatch, X-Ray, and CloudTrail, which help you gain insights into your Lambda functions’ performance, trace requests, and monitor your entire architecture. By setting up alarms and automating responses, you can ensure that your application remains healthy and responsive.
We combine all of these AWS services to get full coverage. Also on alert states, we notify the team through specific Slack channels, and we fight constantly against false positives to keep these channels as quiet as possible when no intervention from the team is required. Now due to the fact that some failures are expected, this is a complicated thing to get right so you only get notified for what “matters”.
Emphasize Resilience
Apart from the classic resiliency strategies for unexpected outages from AWS (multi-AZ, multi-region, etc), in serverless, it’s important to have strategies in place from the beginning to mitigate all the issues if the various places that can go wrong, like:
- Internal failures due to downstream services
- Internal failures due to bugs (oops!)
- Message payload failures
- Orchestration failures
- AWS throttling errors
- AWS random errors (yes, they do occur)
- Lambda timeouts
Which means that you need to figure out what happens when it fails, and more importantly what happens with the payload, especially if the task still needs to be run. How you can find it again and how to re-drive it through the system. Ideally this should be automatic, but what happens if the automatic system failed, or tried multiple times and couldn’t succeed?
To this end we make extended use of Dead-Letter Queues (DLQs) with redrive strategies and alerts on failing to empty the queue, meaning the processing of the message cannot be done.
Orchestration
SQS, SNS, Dynamo streams, kinesis streams, API gateways, crons, etc, all are very useful to stream, circulate, and trigger processes and lambda functions in particular, but you quickly find yourself in a sea of events that happen whenever wherever, or just wanting to call a Lambda after another one has finished, or orchestrate various operations and procedures in various AWS services. That’s where the Step Functions are coming into place. They are state machines that you can just build using the visual editor and orchestrate any kind of complicated series of events.
What the catch, you said? Well, there is a limit of 25 thousand events per standard step function (there is also the express but I wouldn’t recommend it, I’ll write another article about step functions and I’ll dive into this). Which means if you have a lot of loops happening (maybe because you broke your lambdas into small pieces for the time limit issue like us), you will end up having to also break your step functions into smaller state machines and call off from the other. It quickly gets fairly complicated, however it still is a great tool that allows you to orchestrate anything fast and easily.
Cost
As we said cost calculation is relatively simple it’s:
“cost of lambda = memory * execution time ms”
Or to be more precise
“cost of lambda = memory * round_up(execution time ms, 100)”
So with us running 200 million of them, it is time to answer the one of the questions you’ve probably been waiting for.
“Was it actually more cost efficient than just running a couple of servers?”
Well let’s see what the maths say:
First of all let’s calculate how many servers would we need if we were to replace all our lambdas by a set of EC2 servers that had the same specs, for the last year, and taking the average duration per lambda run we had.
In our case these relations could be described by the relation in the chart, where medium instance is the one with the average specs of our lambdas, and xlarge the one that satisfies our most demanding lambda requirements. (Will explain it more, and beautify it), showing the number of servers to the number of monthly invocations.
We see that in our case the ~17 million average monthly invocations would be about 25 on-demand, always-on medium instances or 6 xlarge ones. Which would most definitely satisfy the actual needs we’ve had the past year.
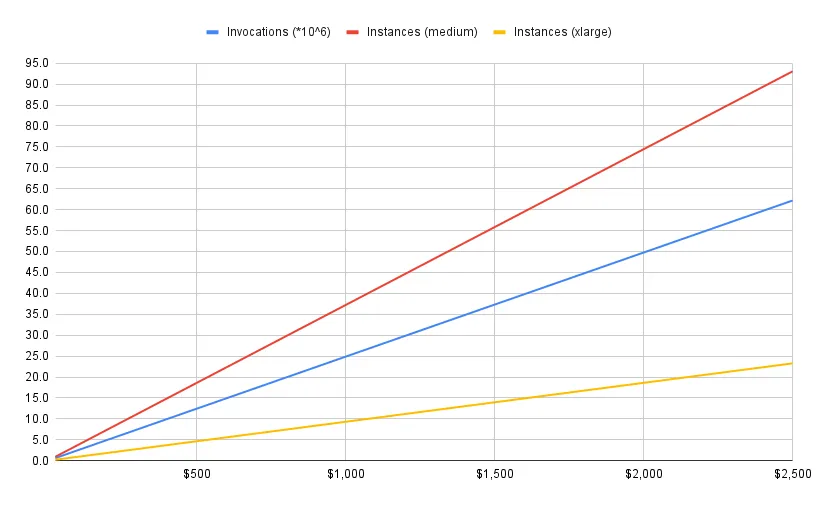
monthly cost per millions of lambda invocations, number of xlarge and number of medium EC2 servers
So if it is in the end more expensive than just having a couple of servers running all the time (not even taking into account dynamic scaling etc), why would anyone do it? Well, why did we do it at least. We did it because it allowed our team to:
- Spend less time on infrastructure scaling concerns, and focus more on our goals
- Be ready for almost any load at any time, sudden growth was less of a fear, so when it happened we could focus on customers issues, and not infrastructure
So in that essence we were hoping to exchange money for time to focus on other things, and less stress for our team. Did we succeed? Hard to tell, no one really knows how it would have been if we had gone the other direction.
Conclusion
In conclusion, let’s see where we stand with regards to these bugging questions we had when we started:
- Is it easier to spin up: absolutely!
- Is it easier to maintain: No really, just different.
- Does it make your team go faster: It makes starting or making a new “service” faster, but overall you will end up spending that time elsewhere, eg monitoring.
- Is it cheaper: When you have no traffic it absolutely is, later on, it quickly isn’t.
- Can it scale more easily: Only for your very first customers, after that you have same amount of concerns, a lot of the same and some slightly different, but it definitely isn’t fire-and-forget scalability
And for us, was it worth it? Probably, especially in the beginning, but as costs increase and traffic becomes more predictable we might mix it more with plain, old servers.
Overall, we’ve learned valuable lessons about scaling, resource allocation, storage, execution time, monitoring, resilience, and cost efficiency and how these affect each other.
We were also reminded multiple times that:
“even if something is “infinitely” scaling, the hardest part is that everything that it interacts with needs to be “equally infinitely” scalable”
Which in reality is not easy to achieve.
Our decision to go serverless aimed to save time, reduce infrastructure concerns, and be ready for any growth at any time. While it has its advantages, the cost-efficiency of serverless depends on the project’s specific needs and priorities, and the complexity of use when it comes to actual real-world applications is, as always, more than initially expected or wished for.
#reads #adadot #serverless #lambdas #aws #software architecture