The following is a summary on how the web3.storage platform is designed. Web3.storage is a cloud storage provider that runs on IPFS (Inter Planetary File System), and is used by Web3 dApps. An interesting detail of Web3.storage, is that they allow changing contents of a folder, without changing the original IPFS CID.
https://blog.web3.storage/posts/web3-storage-architecture
web3.storage provides scalability and performance not seen before in a hosted IPFS solution. This includes both the ability to upload data and to read the data from the network. This allows users to easily take advantage of content addressing at scale.
But how does web3.storage work in practice? Like any other IPFS service or node, it’s still a service that participates in a distributed, peer-to-peer network. So although users get the benefits of IPFS (resiliency! security! immutability! no lock in!), there are nuances in how the system is architected to provide an upload and download experience that just works from a user’s perspective. Framed another way, web3.storage’s approach brings the performance of web2 without compromising the benefits and guarantees web3 protocols give.
In this post, we give a high-level overview on how web3.storage is architected. The hope is that, by understanding what goes on under the hood better, users can utilize web3.storage in the best way that works for them.
Stage 1: Client-side CAR generation
As you might know, one of the things that makes IPFS unique is that data is referenced using a hash of the data, or a CID. It does this by creating a Merkle DAG of the data.
Without getting into the weeds too much, it’s important to note that:
- This requires the data to be processed before it can be made available on the IPFS network
- If you do this data processing yourself, then you get a strong cryptographic security guarantee - you created the hash of the uploaded data yourself, allowing you to cryptographically verify that content in the future
As a result, when a user uploads a file to web3.storage, web3.storage’s client library first generates a Merkle DAG and the associated CID on the client-side. The user does not need to trust that web3.storage is giving back the right hash since they do it themselves.
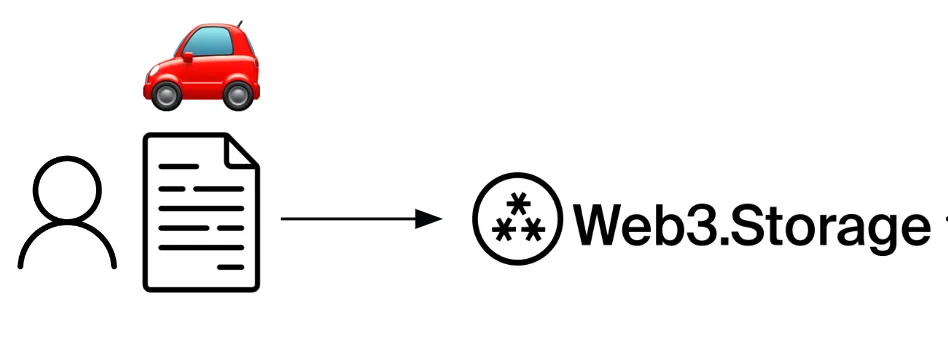
Now that the data is processed, the client serializes the Merkle DAG into a CAR file (or more than one if the upload is large). This is what is sent to web3.storage, and allows web3.storage to preserve the CID generated client-side!
If you want to learn more about this CAR generation step, check out libraries like ipfs-car, which allows you to generate a CAR file from the command line independent of the upload flow. You can also generate a CAR from a Kubo node by running ipfs dag export.
Stage 2: Hot storage and serving content
Once the CAR file is uploaded to the web3.storage API, what happens next?
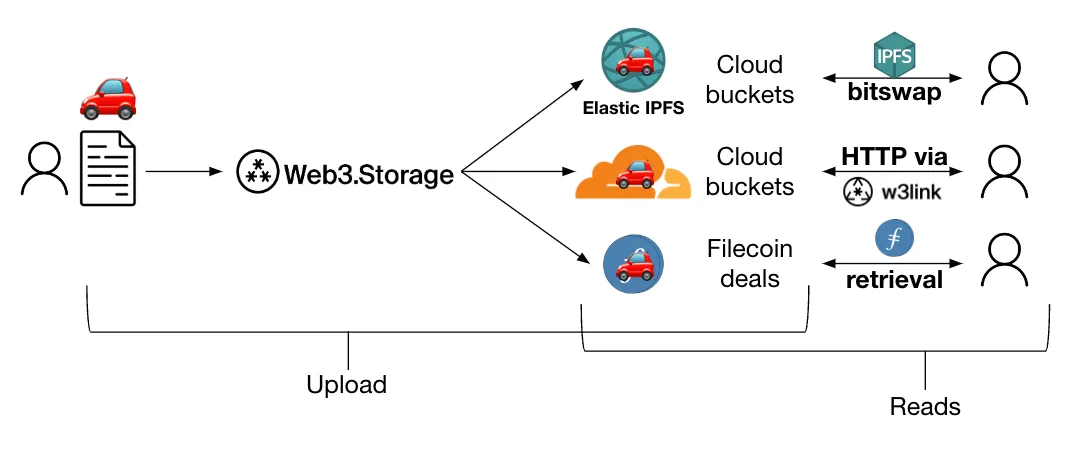
The CAR file is immediately stored in a two places that “speak” IPFS. Both of these places can take a requested content CID and send back the associated content. Consequently, these places each also need to be able to reassemble the content from the data in the CAR files (since the latter is what web3.storage stores at rest).
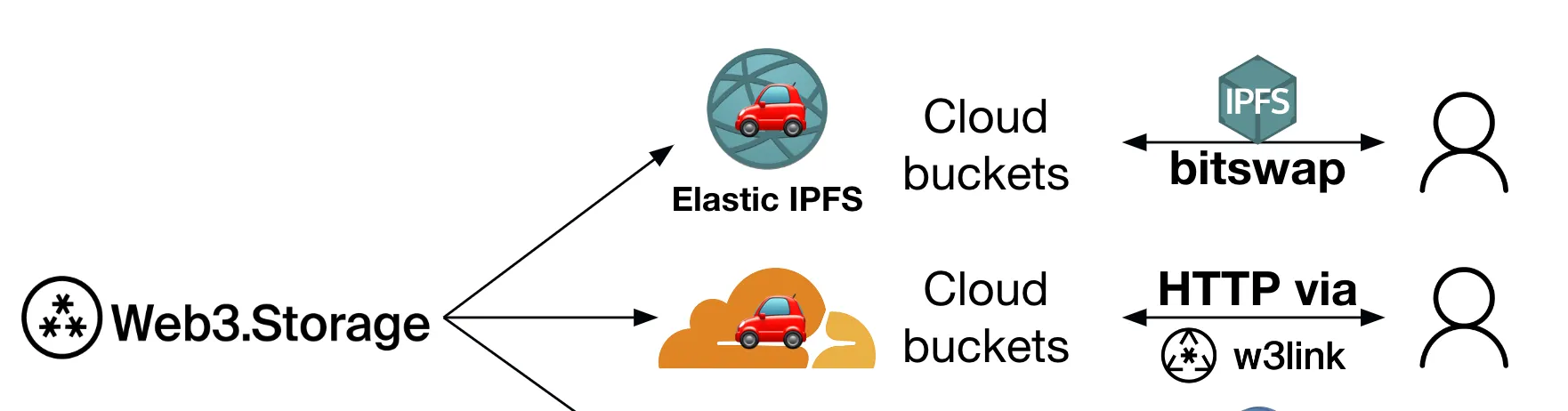
The first place is in our Elastic IPFS instance. This is what allows for the content to be available over the public IPFS network. In other words, when you grab content from an IPFS node - it could be one you’re running yourself, a public IPFS gateway like ipfs.io, etc. - it is served from our Elastic IPFS instance reading the content from the CAR files stored there.
The other place is in the w3link gateway. w3link is an IPFS HTTP gateway that is part of the web3.storage platform, and can return any content that is available on the public IPFS network. However, it is able to serve content stored with web3.storage especially quickly. By storing CAR files of uploads on the edge, w3link can skip asking the broader IPFS network for the location of the data if it has the right CAR files, using Freeway to assemble requested content.
In terms of timing and availability, as soon as an upload is complete, its content is immediately available in w3link over HTTP. It becomes available on the broader IPFS network via Elastic IPFS a few seconds later since Elastic IPFS needs a bit of time to process the upload. More generally, w3link is the fastest and most reliable way to read content stored on web3.storage since the infrastructure receiving the read request also possesses the data itself. Though Elastic IPFS is even once content is available on the broader IPFS network, requests to the IPFS network have to go through content discovery.
Note that how Elastic IPFS and w3link “speak” IPFS is different than how a Kubo node operates. Unlike in Kubo nodes, Elastic IPFS and w3link store data in CAR files at rest - which is one of the main reasons these solutions scale really well (to 5 billion blocks and beyond)!
Stage 3: Cold storage in Filecoin deals
The final stage in the pipeline is storing data in Filecoin deals. Filecoin deals are made with storage providers who dedicate their hard drive space to the open Filecoin storage marketplace. When a storage client like web3.storage and a storage provider come to terms on a storage deal, the storage provider starts storing CAR files containing the client’s data. For the duration of the deal, the storage provider periodically needs to submit cryptographic proofs that they are actually storing the exact data and number of replicas they promised.
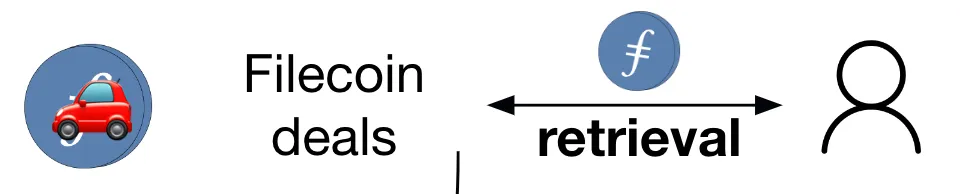
These proofs can then be mathematically verified by other storage providers in the network, and once verified, these proofs get written to the public Filecoin blockchain. As a result, as a web3.storage user, you can check the Filecoin blockchain to verify that your data is being stored as promised.
Because data needs to be aggregated into deals, it can take 1 to 3 days for data to go from upload to stored in a Filecoin deal. However, these storage deals are extremely inexpensive (historically, they’ve been free!). This is due to the Filecoin Plus mechanism (which allows storage providers storing “useful” data to increase their probability of winning a block reward in the network) and the sheer amount of storage volume available on the network.
It is best to view Filecoin deals as cold storage, since it can take some time and UX hurdles to read data from Filecoin storage providers. However, this is quickly improving. Realistically, these copies will continue to be cold storage for a while, but increasingly cold storage copies you can rely on in many production use cases (especially when supplemented with caching like what w3name provides). And as the Filecoin network improves with projects like the Filecoin Virtual Machine, there will be increasing potential in what you can do with data on Filecoin!
Future: Consumption-based payment
You might ask - why store data in three places? Why not save costs, or charge less for storage by storing data in fewer places?
Well, each place we store data is for a specific purpose - very hot copies of the data available over HTTP in w3link, medium-hot copies of the data available over the public IPFS network in Elastic IPFS, and colder, but verifiable, copies in Filecoin storage that will increasingly get hotter over time as the network improves. Each one of these copies fills a user need that’s been asked for by our users, and for the amount users pay for storage (currently $0.08 to $0.10 per GiB per month), you get all three.
In the next year, we hope to offer consumption-based pricing, giving users the choice on where they store their data, allowing them to pick the physical storage locations that specifically fulfill their needs. Don’t need data available on the general IPFS network? Then don’t pay for a copy in Elastic IPFS. Just need cold storage? Pay little to nothing for just copies in Filecoin deals.
And because all the data is referenced using IPFS content addresses, the way your application interacts with the data doesn’t change at all due to where it’s physically being stored (a concept we call “data anywhere”). The elimination of friction from moving data around heavily reduces the lock-in that cloud storage providers traditionally exert over their users. Our vision is for us to function as a marketplace in this regard, letting users pick which physical storage providers make the most sense for which subsets of their data. In the long-run, we think this commoditizes cloud storage and brings value to users.