The following is an overview of a good debugger: one that can provide basic functionalities such as breakpoints, memory visualization/inspection, REPL support and going up to more complex features such as rewinding the program state and controlling thread execution. The article is very focused on C++ and debug tools like GDB, LLDB and Visual Studio, but most of the concepts should be available on other languages with tools such as Jetbrains IDEs and Visual Studio Code.
For me, one of the best features this article introduced me is Time Travel, which allows you to reconstruct the program state of until a snapshot that was recorded previously, and then you can continue your normal debugging life! Watch the following video as a reference on how you can leverage these features for game development:
https://werat.dev/blog/what-a-good-debugger-can-do/

When people say “debuggers are useless and using logging and unit-tests is much better,” I suspect many of them think that debuggers can only put breakpoints on certain lines, step-step-step through the code, and check variable values. While any reasonable debugger can indeed do all of that, it’s only the tip of the iceberg. Think about it; we could already step through the code 40 years ago, surely some things have changed?
Tl;dr – in this episode of old-man-yells-at-cloud, you will learn that a good debugger supports different kinds of breakpoints, offers rich data visualization capabilities, has a REPL for executing expressions, can show the dependencies between threads and control their execution, can pick up changes in the source code and apply them without restarting the program, can step through the code backward and rewind the program state to any point in history, and can even record the entire program execution and visualize control flow and data flow history.
I should mention that the perfect debugger doesn’t exist. Different tools support different features and have different limitations. As usual, there’s no one-size-fits-all solution, but it’s important to understand what’s theoretically possible and what we should strive for. In this article, I will describe different debugging features and techniques and discuss the existing tools/products that offer them.
Disclaimer. In this article I mention various free and commercial products as examples. I’m not being paid or incentivised in any other way by the companies behind those products (although I will not say no to free swag should they decide to send me some cough-cough). My goal is to raise awareness and challenge the popular belief that “debuggers are useless, let’s just printf”.
Breakpoints, oh my breakpoints #
Let’s start with the basics – breakpoints. They’ve been with us since the dawn of time and every debugger supports them. Put a breakpoint on some line in the code and the program will stop when the execution gets to that line. As basic as it gets. But modern debuggers can do a lot more than that.
Column breakpoints. Did you know it’s possible to put breakpoints not just on a specific line, but on a line+column as well? If a single line of source code contains multiple expressions (e.g. function calls like foo() + bar() + baz()), then you can put a breakpoint in the middle of the line and skip directly to that point of execution. LLDB has supported this for a while now, but the IDE support might be lacking. Visual Studio has a command called Step into specific, which solves a similar problem – it allows you to choose which function to step into if there are multiple calls on the same line.
Conditional breakpoints. Typically there’s a bunch of extra options you can set on breakpoints. For example, you can specify the “hit count” condition to trigger the breakpoint only after a certain amount of times it was hit or every Nth iteration. Or use an even more powerful concept – conditional expressions, – to trigger the breakpoint when your application is in a certain state. For example, you can make the breakpoint trigger only when the hit happens on the main thread and monster->name == "goblin". Visual Studio debugger also supports the “when-changes” type of conditional expressions – trigger the breakpoint when the value of monster->hp changes compared to the previous time the breakpoint was hit.
Tracing breakpoints (or tracepoints). But what if breakpoints didn’t break? 🤔 Say no more, instead of stopping the execution, we can print a message to the output. And not just a simple string literal like “got here lol”; the message can contain expressions to calculate and embed values from the program, e.g. “iteration #{i}, current monster is {monster->name}”. Essentially, we’re injecting printf calls to random places in our program without rebuilding and restarting it. Neat, right?
Data breakpoints. Breakpoints also don’t have to be on a specific line, address or function. All modern debuggers support data breakpoints, which means the program can stop whenever a specific location in memory is written to. Can’t figure out why the monster is randomly dying? Set a data breakpoint on the location of monster->hp and get notified whenever that value changes. This is especially helpful in debugging situations where some code is writing to memory that it shouldn’t. Combine it with printing messages and you get a powerful logging mechanism that can’t be achieved with printf!
Data visualization #
Another basic debugging feature – data inspection. Any debuggers can show the values of variables, but good debuggers offer rich capabilities for custom visualizers. GDB has pretty printers, LLDB has data formatters and Visual Studio has NatVis. All of these mechanisms are pretty flexible and you can do virtually anything when visualizing your objects. It’s an invaluable feature for inspecting complex data structures and opaque pointers. For example, you don’t need to worry about the internal representation of a hash map, you can just see the list of key/value entries.
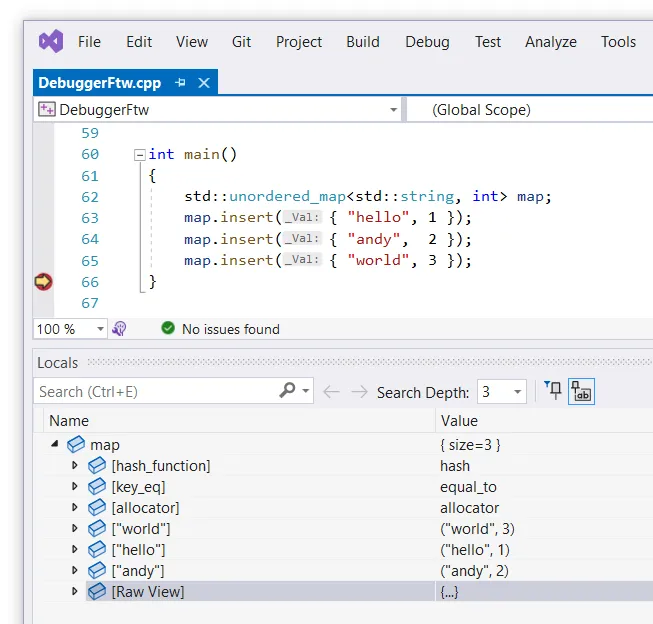
These visualizers are extremely useful, but good debuggers can do even better. If you have a GUI, why limit yourself to “textual” visualization? The debugger can show data tables and charts (e.g. results of SQL queries), render images (e.g. icons or textures), play sounds and so much more. The graphical interface opens up infinite possibilities here and these visualizers are not even that hard to implement.
Expression evaluation #
Most modern debuggers support expression evaluation. The idea is that you can type in an expression (typically using the language of your program) and the debugger will evaluate it using the program state as context. For example, you type monsters[i]->get_name() and the debugger shows you "goblin" (where monsters and i are variables in the current scope). Obviously this is a giant can of worms and the implementation varies a lot in different debuggers and for different languages.
For example, Visual Studio debugger for C++ implements a reasonable subset of C++ and can even perform function calls (with some limitations). It uses an interpreter-based approach, so it’s pretty fast and “safe”, but doesn’t allow executing truly arbitrary code. Same thing is done by GDB. LLDB on the other hand uses an actual compiler (Clang) to compile the expression down to the machine code and then executes it in the program (though in some situations it can use interpretation as an optimization). This allows executing virtually any valid C++!
(lldb) expr
Enter expressions, then terminate with an empty line to evaluate:
1: struct Foo {
2: int foo(float x) { return static_cast<int>(x) * 2; }
3: };
4: Foo f;
5: f.foo(3.14);
(int) $0 = 6
Expression evaluation is a very powerful feature which opens up a lot of possibilities for program analysis and experimentation. By calling functions you can explore how your program behaves in different situations and even alter its state and execution. The debuggers also often use expression evaluation to power other features, like conditional breakpoints, data watches and data formatters.
Concurrency and multithreading #
Developing and debugging multithreaded applications is hard. Many concurrency-related bugs are tricky to reproduce and it’s not uncommon for the whole program to behave very differently when run under a debugger. Still, good debuggers can offer a lot of help here.
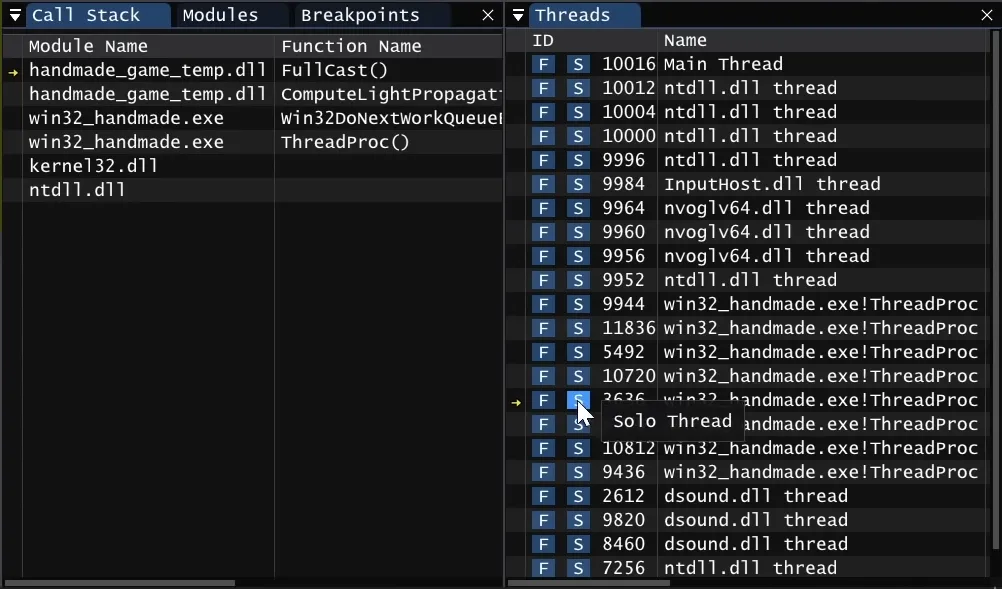
A great example of a situation where a debugger can save you a lot of time is debugging deadlocks. If you managed to catch your application in a state of deadlock, you’re in luck! A good debugger will show the call stacks of all threads and the dependencies between them. It’s very easy to see which threads are waiting for which resources (e.g. mutexes) and who’s hogging those resources. A while ago I wrote an article about a case of debugging deadlocks in Visual Studio, see for yourself how easy it is.
A very common problem with developing and debugging multithreaded applications is that it’s hard to control which threads are executed when and in which order. Many debuggers follow the “all-or-nothing” policy meaning that when a breakpoint is hit the whole program is stopped (i.e. all of its threads). If you hit “continue” all threads start running again. This works ok if the threads in your program don’t overlap, but becomes really annoying when the same code is executed by different threads and the same breakpoints are being hit in random order.
A good debugger can freeze and unfreeze threads. You can select which threads should execute and which should sleep. This makes debugging of heavily parallelized code much much easier and you can also emulate different race conditions and deadlocks. In Visual Studio you can freeze and thaw threads in the UI and GDB has a thing called non-stop mode. RemedyBG has a very convenient UI where you can quickly switch into the “solo” mode and back (demo, relevant part starts at 2:00).
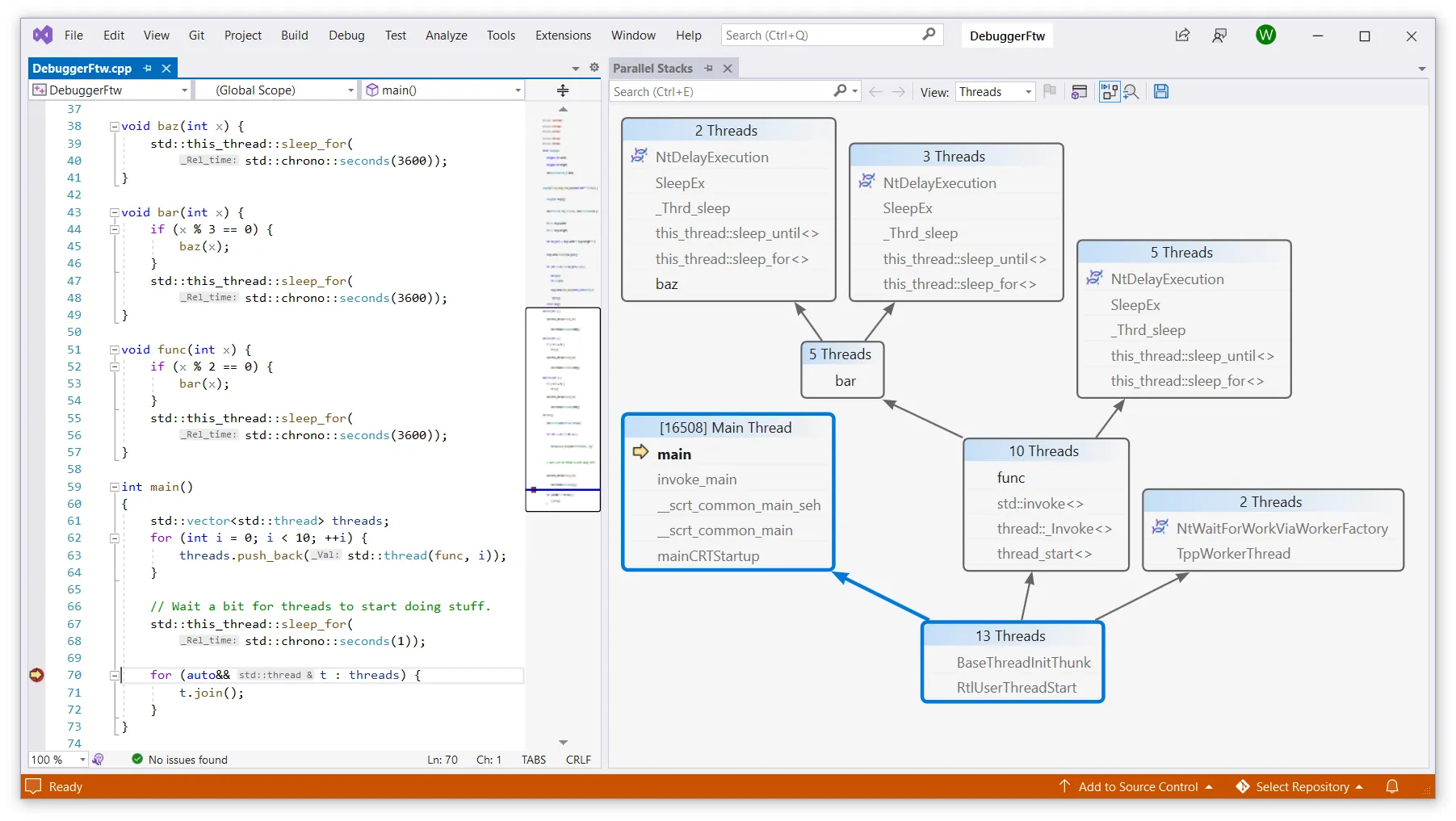
I already mentioned this earlier, but debuggers can show the dependencies between threads. A good debugger also supports coroutines (green threads, tasks, etc) and offers some tools to visualize the current program state. For example, Visual Studio has a feature called Parallel Stacks. In this window you can get a quick overview of the whole program state and see which code is being executed by different threads.
Hot reload #
Imagine a typical debugging sessions. You run the program, load the data, perform some actions and finally get to point where you spot the bug. You put some breakpoints, step-step-step and suddenly realize that a certain “if” condition is wrong – it should be >= instead of >. What do you do next? Stop the program, fix the condition, rebuild the program, run it, load the data, perform some actions… Wait wait. It’s 2023, what do you actually do next?
You fix the condition and save the file. You blink twice and the program picks up the changes in the code! It didn’t restart and it didn’t lose the state, it’s exactly in the place where you left it. You immediately see your fix was incorrect and it should actually be ==. Fix again and voila, the bug is squashed.
This magic-like feature is called hot reload – a good debugger can pick up the changes in the source code and apply them to a live running program without restarting it. Many people who use dynamic or VM-based languages (like JavaScript or Python or Java) know it’s a thing, but not everyone realizes it’s possible for compiled languages like C++ or Rust, too! For example, Visual Studio supports hot reloading for C++ via Edit and Continue. It does have a long list of restrictions and unsupported changes, but it still works reasonably well in many common scenarios (demo).
Another awesome technology is Live++ – arguably, the best hot reload solution available today. It supports different compilers and build systems and can be used with any IDE or debugger. The list of unsupported scenarios is much shorter and many of those are not fundamental restrictions – with enough effort, hot reload can work with almost any kind of changes.
Hot reload is not just about applying the changes to a live program. A good hot reload implementation can help recover from fatal errors like access violation or change the optimization levels (and potentially any other compiler flags) for different compilation units. It can also do that remotely and for multiple processes at the same time. Take a look at this quick demo of Live++ by @molecularmusing:
Hot reload is invaluable in many situations and, honestly, it’s hard to imagine a scenario where it wouldn’t be helpful. Why restart the application when you don’t have to?
Time travel #
Did you ever have a problem where you were stepping through the code and have accidentally stepped too far? Just a little bit, but ugh, the damage is already done. Oh well, let’s restart the program and try again… ⏪ again try and program the restart let’s, well oh ⏯️ No problem, let’s just step backwards a few times. This might feel even more magical than hot reload, but a good debugger can actually travel in time. Do a single step back or put a breakpoint and run in reverse until it’s hit – party debug like it’s 2023, not 1998.
Many debuggers support it in some way. GDB implements time travel by recording the register and memory modifications made by each instruction, which makes it trivial to undo the changes. However, this incurs a significant performance overhead, so it may be not as practical in non-interactive mode. Another popular approach is based on the observation that most of the program execution is deterministic. We can snapshot the program whenever something non-deterministic happens (syscall, I/O, etc) and then we just reconstruct the program state at any moment by rewinding it to the nearest snapshot and executing the code from there. This is basically what UDB, WinDBG and rr do.
Time travel and reverse execution in particular is immensely helpful for debugging crashes. For example, take a typical crash scenario – access violation or segmentation fault. With regular tools we can get a stacktrace when somebody tries to dereference a null pointer. But the stacktrace might not be as useful, what we actually want to know is why the pointer in question is null. With time travel we can put a data breakpoint on the pointer value and run the program in reverse. Now when the breakpoint is triggered we can see exactly how the pointer ended up being null and fix the issue.
Time travel has certain performance overhead, but in some situations it’s totally worth it. A prime candidate use case for that is running tests. Of course, fast tests are better than slow tests, but being able to replay and examine the execution of a particular failure is a huge time saver. Especially when the test is flaky and reproducing the failure takes a lot of time and luck. In fact, rr was originally developed by Mozilla for recording and debugging Firefox tests.
In some cases time travel can be implemented very efficiently if it’s deeply integrated into the whole ecosystem and therefore can assume certain things and cut corners. For example, if most of the program memory is immutable resources loaded from disk, then keeping track of it is much easier and snapshots can be made very compact. An amazing example of such integrated development and debugging experience is Tomorrow Corporation Tech Demo. If you haven’t seen it yet, go and watch right now!
Omniscient debugging #
The last thing on my list for today is a complete game changer in the debugging scene. You won’t believe what it can do with your program! Traditional debugging has a lot of downsides, which you are probably well aware of. Record and replay is a huge step forward, but what if in addition to recording the reproducible program trace we also pre-calculated all individual program states, stored them in a database and built indexes for efficient querying? It sounds impossible, but it’s actually surprisingly feasible. It turns out the program states compress very well, down to <1bit of storage per instruction!
This approach is called omniscient debugging and not only does it solve a bunch of problems that traditional debuggers suffer from (e.g. stack unwinding), but it also opens up the possibilities we didn’t think were possible before. With the whole program history recorded and indexed, you can ask questions like “how many times and where this was variable written?”, “which thread freed this chunk of memory?” or even “how was this specific pixel rendered?”.
If you’re still skeptical, watch this talk – Debugging by querying a database of all program state by Kyle Huey. It explains really well how all of this is possible and why you should look into it. Of course, there are limitations, but many of them are merely implementation details, not fundamental restrictions. I also recommend watching The State Of Debugging in 2022 by Robert O’Callahan (author of rr), which makes a great argument of why omniscient debugging is the future and we should demand better from our tools.
Omniscient debugging is still young, even though the idea goes a few decades back (see Debugging Backwards in Time (2003) by Bil Lewis). The idea is very simple, but an efficient and practical implementation is hard. Even so, the potential is mind-blowing. A great example of a modern omniscient debugger is Pernosco. It has a long list of supported features and use cases and even simple demos look almost unbelievable. Try it for yourself and welcome to the future!
Another awesome tool to try is WhiteBox. It compiles, run and “debugs” the code as you write it, giving you valuable insights into the program flow and structure. It records the execution and allows you to inspect the program state at any moment in time. It’s still in beta and I’m really excited to see what comes out of it. This is what I expected the future would look like and we’re finally getting there :D
To debug or not to debug? #
Every existing debugger has its ups and downs; there’s no silver bullet, but you already knew that. In some situations logging is more convenient, while in others using a time-traveling debugger can shorten the bug investigation from days to minutes. Debugging technologies have come a long way and even though many things are not as impressive as you might expect, there are a lot of interesting features that are definitely worth checking out. Please use debuggers and complain if something is not working. Demand better from your local debugger vendor, only then way will things improve.
#reads #andy hippo #debugger #debugging #gdb #lldb #visual studio #game development #c++