The following is an in-depth explanation on how Rosetta 2 translator works and why it proves to be so fast.
https://dougallj.wordpress.com/2022/11/09/why-is-rosetta-2-fast/
Rosetta 2 is remarkably fast when compared to other x86-on-ARM emulators. I’ve spent a little time looking at how it works, out of idle curiosity, and found it to be quite unusual, so I figured I’d put together my notes.
My understanding is a bit rough, and is mostly based on reading the ahead-of-time translated code, and making inferences about the runtime from that. Let me know if you have any corrections, or find any tricks I’ve missed.
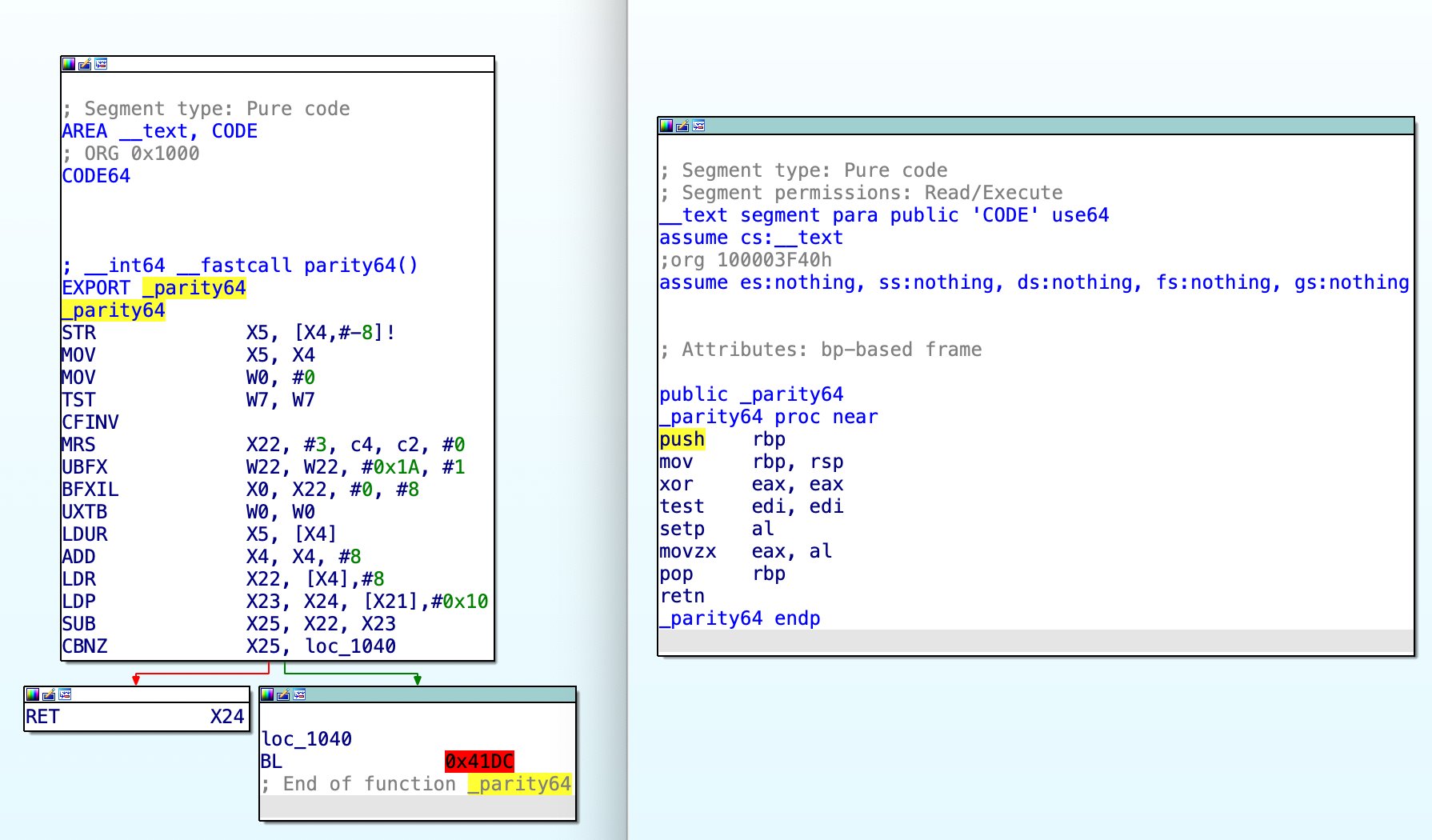
IDA Pro screenshot: side-by-side comparison of Rosetta 2 ahead-of-time code, and the original x86 code, for a function incorrectly named “parity64”, that computes the 8-bit parity an argument using the x86 parity-flag.
Ahead-of-time translation
Rosetta 2 translates the entire text segment of the binary from x86 to ARM up-front. It also supports just-in-time (JIT) translation, but that is used relatively rarely, avoiding both the direct runtime cost of compilation, and any indirect instruction and data cache effects.
Other interpreters typically translate code in execution order, which can allow faster startup times, but doesn’t preserve code locality.
Usually one-to-one translation
[Correction: an earlier version of this post said that every ahead-of-time translated instruction was a valid entry point. While I still believe it would be valid to jump to almost any ahead-of-time translated instruction, the lookup tables used do not allow for this. I believe this is an optimisation to keep the lookup size small. The prologue/epilogue optimisation was also discovered after the initial version of this post.]
Each x86 instruction is translated to one or more ARM instructions once within the ahead-of-time binary (with the exception of NOPs, which are ignored). When an indirect jump or call sets the instruction pointer to an arbitrary offset in the text segment, the runtime will look up the corresponding translated instruction, and branch there.
This uses an x86 to ARM lookup table that contains all function starts, and other basic blocks that are otherwise not referenced. If it misses this, for example while handling a switch-statement, it can fall back to the JIT.
To allow for precise exception handling, sampling profiling, and attaching debuggers, Rosetta 2 maintains a full mapping from translated ARM instructions to their original x86 address, and guarantees that the state will be canonical between each instruction.
This almost entirely prevents inter-instruction optimisations. There are two known exceptions. The first is an “unused-flags” optimisation, which avoids calculating x86 flags value if they are not used before being overwritten on every path from a flag-setting instruction. The other combines function prologues and epilogues, combining push and pop instructions and delaying updates of the stack pointer. In the ARM to x86 address mapping these appear as though they were a single instruction.
There are some tradeoffs to keeping state canonical between each instruction:
- Either all emulated register values must be kept in host registers, or you need load or store instructions every time certain registers are used. 64-bit x86 has half as many registers as 64-bit ARM, so this isn’t a problem for Rosetta 2, but it would be a significant drawback to this technique for emulating 64-bit ARM on x86, or PPC on 64-bit ARM.
- There are very few inter-instruction optimisations, leading to surprisingly poor code generation in some cases. However, in general, the code has already been generated by an optimising compiler for x86, so the benefits of many optimisations would be limited.
However there are significant benefits:
- Generally translating each instruction only once has significant instruction-cache benefits – other emulators typically cannot reuse code when branching to a new target.
- Precise exceptions, without needing to store much more information than instruction boundaries.
- The debugger (LLDB) and works with x86 binaries, and can attach to Rosetta 2 processes.
- Having fewer optimisations simplifies code generation, making translation faster. Translation speed is important for both first-start time (where tens of megabytes of code may be translated), and JIT translation time, which is critical to the performance of applications that use JIT compilers.
Optimising for the instruction-cache might not seem like a significant benefit, but it typically is in emulators, as there’s already an expansion-factor when translating between instruction sets. Every one-byte x86 push becomes a four byte ARM instruction, and every read-modify-write x86 instruction is three ARM instructions (or more, depending on addressing mode). And that’s if the perfect instruction is available. When the instructions have slightly different semantics, even more instructions are needed to get the required behaviour.
Given these constraints, the goal is generally to get as close to one-ARM-instruction-per-x86-instruction as possible, and the tricks described in the following sections allow Rosetta to achieve this surprisingly often. This keeps the expansion-factor as low as possible. For example, the instruction size expansion factor for an sqlite3 binary is ~1.64x (1.05MB of x86 instructions vs 1.72MB of ARM instructions).
(The two lookups (one from x86 to ARM and the other from ARM to x86) are found via the fragment list found in LC_AOT_METADATA. Branch target results are cached in a hash-map. Various structures can be used for these, but in one binary the performance-critical x86 to ARM mapping used a two-level binary search, and the much larger, less-performance-critical ARM to x86 mapping used a top-level binary search, followed by a linear scan through bit-packed data.)
Memory layout
An ADRP instruction followed by an ADD is used to emulate x86’s RIP-relative addressing. This is limited to a +/-1GB range. Rosetta 2 places the translated binary after the non-translated binary in memory, so you roughly have [untranslated code][data][translated code][runtime support code]. This means that ADRP can reference data and untranslated code as needed. Loading the runtime support functions immediately after the translated code also allows translated code to make direct calls into the runtime.
Return address prediction
All performant processors have a return-address-stack to allow branch prediction to correctly predict return instructions.
Rosetta 2 takes advantage of this by rewriting x86 CALL and RET instructions to ARM BL and RET instructions (as well as the architectural loads/stores and stack-pointer adjustments). This also requires some extra book-keeping, saving the expected x86 return-address and the corresponding translated jump target on a special stack when calling, and validating them when returning, but it allows for correct return prediction.
This trick is also used in the GameCube/Wii emulator Dolphin.
ARM flag-manipulation extensions
A lot of overhead comes from small differences in behaviour between x86 and ARM, like the semantics of flags. Rosetta 2 uses the ARM flag-manipulation extensions (FEAT_FlagM and FEAT_FlagM2) to handle these differences efficiently.
For example, x86 uses “subtract-with-borrow”, whereas ARM uses “subtract-with-carry”. This effectively inverts the carry flag when doing a subtraction, as opposed to when doing an addition. As CMP is a flag-setting subtraction without a result, it’s much more common to use the flags from a subtraction than an addition, so Rosetta 2 chooses inverted as the canonical form of the carry flag. The CFINV instruction (carry-flag-invert) is used to invert the carry after any ADD operation where the carry flag is used or may escape (and to rectify the carry flag, when it’s the input to an add-with-carry instruction).
x86 shift instructions also require complicated flag handling, as it shifts bits into the carry flag. The RMIF instruction (rotate-mask-insert-flags) is used within rosetta to move an arbitrary bit from a register into an arbitrary flag, which makes emulating fixed-shifts (among other things) relatively efficient. Variable shifts remain relatively inefficient if flags escape, as the flags must not be modified when shifting by zero, requiring a conditional branch.
Unlike x86, ARM doesn’t have any 8-bit or 16-bit operations. These are generally easy to emulate with wider operations (which is how compilers implement operations on these values), with the small catch that x86 requires preserving the original high-bits. However, the SETF8 and SETF16 instructions help to emulate the flag-setting behaviour of these narrower instructions.
Those were all from FEAT_FlagM. The instructions from FEAT_FlagM2 are AXFLAG and XAFLAG, which convert floating-point condition flags to/from a mysterious “external format”. By some strange coincidence, this format is x86, so these instruction are used when dealing with floating point flags.
Floating-point handling
x86 and ARM both implement IEEE-754, so the most common floating-point operations are almost identical. One exception is the handling of the different possible bit patterns underlying NaN values, and another is whether tininess is detected before or after rounding. Most applications won’t mind if you get this wrong, but some will, and to get it right would require expensive checks on every floating-point operation. Fortunately, this is handled in hardware.
There’s a standard ARM alternate floating-point behaviour extension (FEAT_AFP) from ARMv8.7, but the M1 design predates the v8.7 standard, so Rosetta 2 uses a non-standard implementation.
(What a coincidence – the “alternative” happens to exactly match x86. It’s quite funny to me that ARM will put “Javascript” in the description of an instruction, but needs two different euphemisms for “x86”.)
Total store ordering (TSO)
One non-standard ARM extension available on the Apple M1 that has been widely publicised is hardware support for TSO (total-store-ordering), which, when enabled, gives regular ARM load-and-store instructions the same ordering guarantees that loads and stores have on an x86 system.
As far as I know this is not part of the ARM standard, but it also isn’t Apple specific: Nvidia Denver/Carmel and Fujitsu A64fx are other 64-bit ARM processors that also implement TSO (thanks to marcan for these details).
Apple’s secret extension
There are only a handful of different instructions that account for 90% of all operations executed, and, near the top of that list are addition and subtraction. On ARM these can optionally set the four-bit NZVC register, whereas on x86 these always set six flag bits: CF, ZF, SF and OF (which correspond well-enough to NZVC), as well as PF (the parity flag) and AF (the adjust flag).
Emulating the last two in software is possible (and seems to be supported by Rosetta 2 for Linux), but can be rather expensive. Most software won’t notice if you get these wrong, but some software will. The Apple M1 has an undocumented extension that, when enabled, ensures instructions like ADDS, SUBS and CMP compute PF and AF and store them as bits 26 and 27 of NZCV respectively, providing accurate emulation with no performance penalty.
Fast hardware
Ultimately, the M1 is incredibly fast. By being so much wider than comparable x86 CPUs, it has a remarkable ability to avoid being throughput-bound, even with all the extra instructions Rosetta 2 generates. In some cases (iirc, IDA Pro) there really isn’t much of a speedup going from Rosetta 2 to native ARM.
Conclusion
I believe there’s significant room for performance improvement in Rosetta 2, by using static analysis to find possible branch targets, and performing inter-instruction optimisations between them. However, this would come at the cost of significantly increased complexity (especially for debugging), increased translation times, and less predictable performance (as it’d have to fall back to JIT translation when the static analysis is incorrect).
Engineering is about making the right tradeoffs, and I’d say Rosetta 2 has done exactly that. While other emulators might require inter-instruction optimisations for performance, Rosetta 2 is able to trust a fast CPU, generate code that respects its caches and predictors, and solve the messiest problems in hardware.
You can follow me at @[email protected].
Update: SSE2 support
After reading some comments I realised this was a significant omission from the original post. Rosetta 2 provides full emulation for the SSE2 SIMD instruction set. These instructions have been enabled in compilers by default for many years, so this would have been required for compatibility. However, all common operations are translated to a reasonably-optimised sequence of NEON operations. This is critical to the performance of software that has been optimised to use these instructions.
Many emulators also use this SIMD to SIMD translation approach, but other use SIMD to scalar, or call out to runtime support functions for each SIMD operation.
Update: Unused flag optimisation
This is one of two inter-instruction optimisations mentioned earlier, but it deserves its own section. Rosetta 2 avoids computing flags when they are unused and don’t escape. This means that even with the flag-manipulation instructions, the vast majority of flag-setting x86 instructions can be translated to non-flag-setting ARM instructions, with no fix-up required. This improves instruction count and size a lot.
It’s even more valuable for Rosetta 2 in Linux VMs. In VMs, Rosetta is unable to enable the Apple parity-flag extension, and instead computes the value manually. (It may or may not also compute the adjust-flag). This is relatively expensive, so it’s very valuable to avoid it.
Update: Prologue/epilogue combining
The last inter-instruction optimisation I’m aware of is prologue/epilogue combining. Rosetta 2 finds groups of instructions that set up or tear down stack frames, and merges them, pairing loads and stores, and delaying stack-pointer updates. This is equivalent to the “stack engine” found in hardware implementations of x86.
For example, the following prologue:
push rbp
mov rbp, rsp
push rbx
push rax
Becomes:
stur x5, [x4,#-8]
sub x5, x4, #8
stp x0, x3, [x4,#-0x18]!
This greatly reduces the number of loads, stores, and arithmetic instructions that modify the stack-pointer, improving performance and code size. These paired loads and stores execute as a single operation on the Apple M1, which, as far as I know, isn’t possible on x86 CPUs, giving Rosetta 2 an advantage here.
Appendix: Research Method
This exploration was based on the methods and information described in Koh M. Nakagawa’s excellent Project Champollion.
To see ahead-of-time translated Rosetta code, I believe I had to disable SIP, compile a new x86 binary, give it a unique name, run it, and then run otool -tv /var/db/oah/*/*/unique-name.aot (or use your tool of choice – it’s just a Mach-O binary). This was done on an old version of macOS, so things may have changed and improved since then.
Update: Appendix: Compatibility
Although it has nothing to do with why Rosetta 2 is fast, there are a couple of impressive compatibility features that seem worth mentioning.
Rosetta 2 has a full, slow, software implementation of x87’s 80-bit floating point numbers. This allows software that uses those instructions to run correctly. Windows on Arm approaches this by using 64-bit float operations, which generally works, but the decreased precision cause problems on in rare cases. Most software either doesn’t use x87, or was designed to run on older hardware, so even though this emulation is slow, the performance typically works out.
[Update: An earlier version of this post stated that I didn’t believe Windows on Arm handled x87. Thanks to kode54 for correcting this in a comment.]
Rosetta 2 also apparently supports the full 32-bit instruction set for Wine. Support for native 32-bit macOS applications was dropped prior to the launch of Apple Silicon, but support for the 32-bit x86 instruction set allegedly lives on. (I haven’t investigated this myself.)
Share this:
Like this:
Like Loading…
Related
Apple M1: Load and Store Queue MeasurementsApril 8, 2021With 2 comments
Faster CRC32 on the Apple M1May 22, 2022Liked by 3 people
Another approach to portable Javascript Spectre exploitationMarch 16, 2021
#reads #dougall johnson #rosetta #compiler #transpiler #macos #assembly #arm